Or try one of the following: 詹姆斯.com, adult swim, Afterdawn, Ajaxian, Andy Budd, Ask a Ninja, AtomEnabled.org, BBC News, BBC Arabic, BBC China, BBC Russia, Brent Simmons, Channel Frederator, CNN, Digg, Diggnation, Flickr, Google News, Google Video, Harvard Law, Hebrew Language, InfoWorld, iTunes, Japanese Language, Korean Language, mir.aculo.us, Movie Trailers, Newspond, Nick Bradbury, OK/Cancel, OS News, Phil Ringnalda, Photoshop Videocast, reddit, Romanian Language, Russian Language, Ryan Parman, Traditional Chinese Language, Technorati, Tim Bray, TUAW, TVgasm, UNEASYsilence, Web 2.0 Show, Windows Vista Blog, XKCD, Yahoo! News, You Tube, Zeldman
Advanced programming with Java generics | InfoWorld
Technology insight for the enterpriseAdvanced programming with Java generics 21 Nov 2024, 9:00 am
Generics in Java enhance the type safety of your code and make it easier to read. In my last article, I introduced the general concepts of generics and showed examples from the Java Collections Framework. You also learned how to use generics to avoid runtime errors like the ClassCastException.
This article goes into more advanced concepts. I introduce sophisticated type constraints and operations that enhance type safety and flexibility, along with key concepts such as bounded type parameters, which restrict the types used with generics and wildcards and allow method parameters to accept varying types. You’ll also see examples of how to use type erasure for backward compatibility and enable generic methods for type inference.
Generic type inference
Type inference, introduced in Java 7, allows the Java compiler to automatically determine or infer the types of parameters and return types based on method arguments and the target type. This feature simplifies your code by reducing the verbosity of generics usage.
When you use generics, you often specify the type inside angle brackets. For example, when creating a list of strings, you would specify the type as follows:
List myList = new ArrayList();
However, with type inference, the Java compiler can infer the type of collection from the variable to which it is assigned. This allows you to write the above code more succinctly:
List myList = new ArrayList();
With type inference, you don’t need to repeat String in the constructor of ArrayList. The compiler understands that since myList is a List, the ArrayList() must also be a String type.
Type inference helps make your code cleaner and easier to read. It also reduces the chance of errors from specifying generic types, which makes working with generics easier. Type inference is particularly useful in complex operations involving generics nested within generics.
Type inference became increasingly useful in Java 8 and later, where it extended to lambda expressions and method arguments. This allows for even more concise and readable code without losing the safety and benefits of generics.
Bounded and unbounded type parameters
In Java, you can use bounds to limit the types that a type parameter can accept. While bounded type parameters restrict the types that can be used with a generic class or method to those that fulfill certain conditions, unbounded type parameters offer broader flexibility by allowing any type to be used. Both are beneficial.
Unbounded type parameters
An unbounded type parameter has no explicit constraints placed on the type of object it can accept. It is simply declared with a type parameter, usually represented by single uppercase letters like E, T, K, or V. An unbounded type parameter can represent any non-primitive type (since Java generics do not support primitive types directly).
Consider the generic Set interface from the Java Collections Framework:
Set stringSet = new HashSet();
Set employeeSet = new HashSet();
Set customerSet = new HashSet();
Here, E represents an unbounded type parameter within the context of a Set. This means any class type can substitute E. Moreover, the specific type of E is determined at the time of instantiation, as seen in the examples where String, Employee, and Customer replace E.
Characteristics and implications of unbounded type parameters
- Maximum flexibility: Unbounded generics are completely type-agnostic, meaning they can hold any type of object. They are ideal for collections or utilities that do not require specific operations dependent on the type, such as adding, removing, and accessing elements in a list or set.
- Type safety: Although an unbounded generic can hold any type, it still provides type safety compared to raw types like a plain
ListorSetwithout generics. For example, once you declare aSet, you can only add strings to this set, which prevents runtime type errors.
- Errors: Because the type of the elements is not guaranteed, operations that depend on specific methods of the elements are not possible without casting, which can lead to errors if not handled carefully.
Bounded type parameters
A bounded type parameter is a generic type parameter that specifies a boundary for the types it can accept. This is done using the extends keyword for classes and interfaces. This keyword effectively says that the type parameter must be a subtype of a specified class or interface.
The following example demonstrates an effective use of a bounded type parameter:
public class NumericOperations {
// Generic method to calculate the square of a number
public static double square(T number) {
return number.doubleValue() * number.doubleValue();
}
public static void main(String[] args) {
System.out.println("Square of 5: " + square(5));
System.out.println("Square of 7.5: " + square(7.5));
}
}
Consider the elements in this code:
- Class definition:
NumericOperationsis a simple Java class containing a static method square. - Generic method:
squareis a static method defined with a generic type T that is bounded by theNumberclass. This means T can be any class that extendsNumber(likeInteger,Double,Float, and so on). - Method operation: The method calculates the square of the given number by converting it to a double (using
doubleValue()) and then multiplying it by itself. - Usage in main method: The
squaremethod is called with different types of numeric values (intanddouble) that are autoboxed toIntegerandDouble, demonstrating its flexibility.
When to use bounded type parameters
Bounded-type parameters are particularly useful in several scenarios:
- Enhancing type safety: By restricting the types that can be used as arguments, you ensure the methods or classes only operate on types guaranteed to support the necessary operations or methods, thus preventing runtime errors.
- Writing reusable code: Bounded type parameters allow you to write more generalized yet safe code that can operate on a family of types. You can write a single method or class that works on any type that meets the bound condition.
- Implementing algorithms: For algorithms that only make sense for certain types (like numerical operations and comparison operations), bounded generics ensure the algorithm is not misused with incompatible types.
A generic method with multiple bounds
You’ve learned about bounded and unbounded type parameters, so now let’s look at an example. The following generic method requires its parameter to be both a certain type of animal and capable of performing specific actions.
In the example below, we want to ensure that any type passed to our generic method is a subclass of Animal and implements the Walker interface.
class Animal {
void eat() {
System.out.println("Eating...");
}
}
interface Walker {
void walk();
}
class Dog extends Animal implements Walker {
@Override
public void walk() {
System.out.println("Dog walking...");
}
}
class Environment {
public static void simulate(T creature) {
creature.eat();
creature.walk();
}
public static void main(String[] args) {
Dog myDog = new Dog();
simulate(myDog);
}
}
Consider the elements in this code:
- Animal class: This is the class bound: The type parameter must be a subclass of
Animal. - Walker interface: This is the interface bound: The type parameter must also implement the
Walkerinterface. - Dog class: This class qualifies as it extends
Animaland implementsWalker. - Simulate method: This generic method in the
Environmentclass accepts a generic parameter, T, that extendsAnimaland implementsWalker.
Using multiple bounds (T extends Animal and Walker) ensures the simulated method can work with any animal that walks. In this example, we see how bounded generic types leverage polymorphism and ensure type safety.
Wildcards in generics
In Java, a wildcard generic type is represented with the question mark (?) symbol and used to denote an unknown type. Wildcards are particularly useful when writing methods that operate on objects of generic classes. Still, you don’t need to specify or care about the exact object type.
When to use wildcards in Java
Wildcards are used when the exact type of the collection elements is unknown or when the method needs to be generalized to handle multiple object types. Wildcards add flexibility to method parameters, allowing a method to operate on collections of various types.
Wildcards are particularly useful for creating methods that are more adaptable and reusable across different types of collections. A wildcard allows a method to accept collections of any type, reducing the need for multiple method implementations or excessive method overloading based on different collection types.
As an example, consider a simple method, displayList, designed to print elements from any type of List:
import java.util.List;
public class Demo {
public static void main(String[] args) {
List colors = List.of("Red", "Blue", "Green", "Yellow");
List numbers = List.of(10, 20, 30);
displayList(colors);
displayList(numbers);
}
static void displayList(List> list) {
for (Object item : list) {
System.out.print(item + " "); // Print each item on the same line separated by a space
}
System.out.println(); // Print a newline after each list
}
}
The output from this method would be:
Red Blue Green Yellow
10 20 30
Consider the elements of this code:
- List creation: Lists are created using
List.of(), which provides a concise and immutable way to initialize the list with predefined elements. - displayList method: This method accepts a list with elements of any type (
List>). Using a wildcard (?) allows the method to handle lists containing objects of any type.
This output confirms that the displayList method effectively prints elements from both string and integer lists, showcasing the versatility of wildcards.
Lower-bound wildcards
To declare a lower-bound wildcard, you use the ? super T syntax, where T is the type that serves as the lower bound. This means that the generic type can accept T or any of its superclasses (including Object, the superclass of all classes).
Let’s consider a method that processes a list by adding elements. The method should accept lists of a given type or any of its superclasses. Here’s how you might define such a method:
public void addElements(List super Integer> list) {
list.add(10); // This is valid because the list is typed to Integer or a superclass of Integer
}
In this example, List super Integer> can accept a List, a List, or a List because both Number and Object are superclasses of Integer.
Benefits of lower-bound wildcards
Flexibility and compatibility are the main benefits of using lower-bound wildcards:
- Flexibility: A lower-bound wildcard allows methods to work with arguments of different types while still enforcing type safety. This is particularly useful for operations that put elements into a collection.
- Compatibility: Functions that use lower-bound wildcards can operate on a broader range of data types, enhancing API flexibility.
Lower-bound wildcards are particularly useful in scenarios where data is being added to a collection rather than read from it. For example, consider a function designed to add a fixed set of elements to any kind of numeric list:
public void addToNumericList(List super Number> list) {
list.add(Integer.valueOf(5));
list.add(Double.valueOf(5.5));
}
This method can accept a List, List, or any other list where Number is a superclass of the list’s element type.
So, why not use List instead of a wildcard? The reason is flexibility: If we have the displayList method configured to receive a List, we will only be able to pass a List. For example, if we tried passing a List, considering the String type is an Object, we would receive a compilation error:
List stringList = Arrays.asList("hello", "world");
displayList(stringList); // Compilation error here because displayList expects List
public void displayList(List list) {
System.out.println(list);
}
If we want to make a collection flexible enough to receive any type, we must use a wildcard or a type parameter.
Key differences between type parameters and wildcards
You’ve learned about both type parameters and wildcards, two advanced elements in Java generics. Understanding how these elements are different will help you know when to use each of them:
- Flexibility vs. specificity: Wildcards offer more flexibility for methods that operate on various objects without specifying a particular type. Type parameters demand specific types and enforce consistency within the use of the class or method where they are defined.
- Read vs. write: Typically, you use
? extends Typewhen you only need to read from a structure because the items will all be instances ofTypeor its subtypes.? super Typeis used when you need to write to a structure, ensuring that the structure can hold items of typeTypeor any type that is a superclass ofType. Type parametersTare used when both operations are required or when operations depend on each other. - Scope: Wildcards are generally used for broader operations in a limited scope (like a single method), while type parameters define a type that can be used throughout a class or a method, providing more extensive code reuse.
Key differences between upper and lower bounds
Now that we know more about type parameters and wildcards, let’s explore the differences between upper bounds and lower bounds.
List super Animal> is an example of a lower-bound list. It is a lower-bound because Animal is the lowest or least specific class you can use. You can use Animal or any type that is a superclass of Animal (such as Object) to effectively go upward in the class hierarchy to more general types.
- Conceptually, lower bounds set a floor, or a minimum level of generality. You can’t go any lower in generality than this limit.
- The purpose of the lower bound in this example is to allow the list to accept assignments of
Animaland any of its subtypes. A lower bound is used when you want to add objects into a list.
- A lower-bound list is often used when you are writing to the list because you can safely add an
Animalor any subtype ofAnimal(e.g., Dog or Cat) to the list, knowing that whatever the actual list type is, it can hold items of typeAnimalor more generic types (likeObject).
- When you retrieve an item from such a list, all you know is that it is at least an
Object(the most general type in Java), because the specific type parameter could be any superclass ofAnimal. As such, you must explicitly cast it if you need to treat it as anAnimalor any other specific type.
Now let’s look at an upper-bound list: List extends Animal>. In this case, Animal is the highest or most specific class in the hierarchy that you can use. You can use Animal itself or any class that is a subtype of Animal (like Dog or Cat), but you cannot use anything more general than Animal.
- Think of upper bounds as setting a ceiling on how specific the types in your collection can be. You can’t go higher than this limit.
- The purpose of the upper-bound limit is to allow the list to accept assignments of
Animalor any superclass ofAnimal, but you can only retrieve items from it asAnimalor its subtypes.
- This type of list is primarily used when you are reading from the list and not modifying it. You can safely read from it knowing that everything you retrieve can be treated as an
Animalor more specific types (DogorCat); still, you cannot know the exact subtype.
- You cannot add items to an upper-bound list (except for null, which matches any reference type) because you do not know what specific subtype of
Animalthe list is meant to hold. Adding anAnimalcould violate the list’s type integrity if, for example, the list wasList.
Writing bounded lists
When writing lower- and upper-bound lists, remember this:
List super Animal>(lower bound) can addAnimaland its subtypes.
List extends Animal>(upper bound) cannot addAnimalor any subtype (except null).
Reading bounded lists
When reading lower- and upper-bound lists, remember this:
List super Animal>: Items retrieved from a lower-bound list are of an indeterminate type up toObject. Casting is required for this item to be used asAnimal.
List extends Animal>: Items retrieved are known to be at leastAnimal, so no casting is needed to treat them asAnimal.
An example of upper- and lower-bound lists
Imagine you have a method to add an Animal to a list and another method to process animals from a list:
void addAnimal(List super Animal> animals, Animal animal) {
animals.add(animal); // This is valid.
}
Animal getAnimal(List extends Animal> animals, int index) {
return animals.get(index); // No casting needed, returns Animal type.
}
In this setup:
addAnimalcan accept aList,List, etc., because they can all hold anAnimal.getAnimalcan work withList,List, etc., safely returningAnimalor any subtype without risking aClassCastException.
This shows how Java generics use the extends and super keywords to control what operations are safe regarding reading and writing, aligning with the intended operations of your code.
Conclusion
Knowing how to apply advanced concepts of generics will help you create robust components and Java APIs. Let’s recap the most important points of this article.
Bounded type parameters
You learned that bounded type parameters limit the allowable types in generics to specific subclasses or interfaces, enhancing type safety and functionality.
Wildcards
Use wildcards (? extends and ? super) to allow generic methods to handle parameters of varying types, adding flexibility while managing covariance and contravariance. In generics, wildcards enable methods to work with collections of unknown types. This feature is crucial for handling variance in method parameters.
Type erasure
This advanced feature enables backward compatibility by removing generic type information at runtime, which leads to generic details not being maintained post-compilation.
Generic methods and type inference
Type inference reduces verbosity in your code, allowing the compiler to deduce types from context and simplify code, especially from Java 7 onwards.
Multiple bounds in Java generics
Use multiple bounds to enforce multiple type conditions (e.g.,
Lower bounds
These support write operations by allowing additions of (in our example) Animal and its subtypes. Retrieves items recognized as Object, requiring casting for specific uses due to the general nature of lower bounds.
Upper bounds
These facilitate read operations, ensuring all retrieved items are at least (in our example) Animal, eliminating the need for casting. Restricts additions (except for null) to maintain type integrity, highlighting the restrictive nature of upper bounds.
{kind=link}
RHEL AI, JBoss EAP 8 coming to Azure cloud 21 Nov 2024, 1:32 am
Red Hat will be making Red Hat Enterprise Linux AI (RHEL AI) and Red Hat JBoss Enterprise Application Platform (EAP) 8 available on Microsoft’s Azure cloud platform. Both arrangements were announced on November 19.
Through a collaboration with Microsoft, RHEL AI will become available on the Azure Marketplace as an optimized and validated foundation model platform to run in Microsoft Azure environments, Red Hat said. Red Hat describes RHEL AI as a way to streamline the development and deployment of generative AI models. It includes the Granite family of open-source large language models (LLMs) from IBM, InstructLab model alignment tools based on the LAB (Large-Scale Alignment for Chatbots) methodology, and a community-driven approach to model development through the InstructLab project. It also offers a pathway to Red Hat OpenShift AI for tuning and serving these models using the same tools and concepts, the company said. RHEL AI on Microsoft Azure will be available on the Azure Marketplace in December 2024.
Red Hat JBoss EAP 8, an update of the Java application server released in February 2024, is also coming to the Azure Marketplace. JBoss EAP provides a pathway for Java application modernization, Red Hat said, including support for Jakarta EE (Enterprise Edition) 10. The server also helps to address reliability, security, and compliance requirements, Red Hat said. With availability on Azure, users can modernize application development across the hybrid cloud while leveraging Azure services, including Azure Red Hat OpenShift, Azure Virtual Machines, and Azure App Service, according to Red Hat. JBoss EAP 8 on Microsoft Azure is due in coming months.
{kind=link}
Azure Container Apps launches Python, JavaScript interpreters 20 Nov 2024, 10:26 pm
Python code interpreter sessions are generally available for Microsoft’s Azure Container Apps serverless platform for running applications and microservices. The service is also offering custom dynamic sessions, with JavaScript code interpreter capabilities in public preview.
Microsoft announced the general availability of the Python interpreter and custom dynamic sessions on November 19. Dynamic sessions provide fast access to built-in Python code interpreter sandboxes without the need to manage containers. To build advanced AI agents or copilots, large language models (LLMs) often are paired with a code interpreter. The interpreter extends the agent’s ability to perform complex tasks such as solving mathematical and reasoning problems or analyzing data, Microsoft said.
A dynamic session includes a Python code interpreter, which provides sandboxes to execute LLM-generated code in production. Developers can leverage dynamic sessions in LangChain, LlamaIndex, and Semantic Kernel agents with a few lines of code, according to Microsoft. In other applications needing to run untrusted Python code, developers can integrate with Python code interpreter sessions via an HTTP API.
In addition to the built-in Python code interpreter, dynamic sessions can run any custom container. Custom container dynamic sessions now support managed identity. These custom container sessions can be used to create a code container for specific needs, such as preinstalling dependencies or supporting a different language.
JavaScript is also supported in Azure Container Apps dynamic sessions. JavaScript code interpreter sessions can be used in applications to run untrusted code on the Node.js runtime. Developers can get started by creating a Node.js session portal in the Azure portal.
{kind=link}
Azure AI Foundry tools for changes in AI applications 20 Nov 2024, 9:00 am
The way we use artificial intelligence is changing. Chatbots aren’t going away. We’ll continue to use them to deliver basic, natural language, self-service applications. But the future belongs to multimodal applications, built on large language models (LLMs) and other AI models, that act as self-organizing software agents. These more complex AI applications will require more thought, more code, more testing, and more safeguards.
An AI evolution requires a similar evolution in our development tools. Although we’ve seen Power Platform’s Copilot Studio begin to deliver tools for building task-focused agents, more complex AI applications will require a lot more work, even with support from frameworks like Semantic Kernel.
Much of Azure’s current AI tools, beyond its Cognitive Services APIs, are focused on building grounded chatbots, using Microsoft’s Prompt Flow framework to add external vector indexes to LLMs for retrieval-augmented generation (RAG), along with wrapping calls and outputs in its own AI safety tools. It’s a proven approach to building and running Microsoft’s own Copilot services, but if enterprises are to get the next generation of AI services, they need new tools that can help deliver custom agents.
Introducing Azure AI Foundry
At Ignite 2024, Microsoft released its Azure AI Foundry SDK. Instead of focusing on services like Azure AI Studio (as good as it is), the company takes Azure AI development to where the developers are: their development environments. Azure AI Foundry will plug into IDEs and editors such as Visual Studio and Visual Studio Code, as well as into platforms like GitHub. Microsoft describes Azure AI Foundry as “a soup-to-nuts platform for building and evaluating and deploying at-scale AI applications.”
That doesn’t mean an end for Azure AI Studio. Instead, it’s going to get a new role as a portal where you can manage your models and the applications using them. It will serve as a bridge between business and development, allowing application owners, stakeholders, and architects to share necessary metrics about your code.
The new portal will help manage access to tools and services, using your Azure subscription to bring key information into a single view. This helps manage resources and privileges and reduces the risk of security breaches. Knowing what resources you’re using is key to ensuring that you have the right controls in place and that you aren’t overlooking critical infrastructure and services.
More than code with Azure AI Foundry
Part of Azure AI Foundry is an update to the Azure Essentials best practices documentation, which now sensibly sits alongside tools like Azure Migrate, the Cloud Adoption Framework, and the Well Architected guidelines. Development teams should visit this portal for architectural and design best practices developed across Microsoft’s partners and its own services team to help build cloud-powered applications.
Azure AI Foundry will include tools that help you benchmark models and choose the right model for your application. Using the same metrics for different models, you can see which fits your data best, which is most efficient, which is most coherent, and how much they will cost to run. Run this new benchmarking tool on both public training data and your own to make the right decision early, reducing the risk of choosing a model that doesn’t fit your requirements or your data.
The result should be a common platform for developer and business stakeholder collaboration. As modern AI migrates from chatbot to intelligent process automation via agents, this approach is going to become increasingly important. Development teams must understand the business problems they are trying to solve, while business analysts and data scientists will be needed to help deliver the necessary prompts to guide the AI agents.
Alongside the new development tool, Azure is expanding its library of AI models. With nearly 2,000 options, you can find and fine-tune the appropriate model for your business problems. In addition to OpenAI’s LLMs and Microsoft’s own Phi small language model, other options include a range of industry-specific models from well-known vendors, such as Rockwell Automation and Bayer. Additional new features will make it easier and faster to prepare training data and use it to fine-tune models.
Merging AutoGen and Semantic Kernel
Closely related to the launch of Azure AI Foundry is the planned merger of Microsoft Research’s AutoGen agentic AI framework with Semantic Kernel. The combination will help you develop and operate long-running stateful business processes, hosting components in Dapr and Orleans. As AutoGen builds on Orleans, there’s already enough convergence between the stable Semantic Kernel and AutoGen’s multi-agent research project.
AutoGen will remain a research platform for experimenting with complex contextual computing projects. Projects can then be ported to Semantic Kernel, giving you a supported runtime for your agents to run them in production. Microsoft is giving plenty of notice for this transition, which should be in early 2025.
If we’re to deliver business process automation with agentic AI, we need to connect our agents to business processes. That’s easy for Copilot Studio, as it can take advantage of the Power Platform’s existing connector architecture. However, building and managing your own connection infrastructure can be complex, even with services like Azure API Management. Access to enterprise data helps orchestrate agents, and at the same time provides grounding for LLMs using RAG.
Managing AI integrations with Azure AI Agent Service
Alongside Azure AI Foundry, Microsoft is rolling out Azure AI Agent Service to support these necessary integrations with line-of-business applications. Azure AI Agent Service simplifies connections to Azure’s own data platform, as well as to Microsoft 365. If Azure AI Foundry is about taking AI to where developers are, Azure AI Agent Service is taking it to where your business data is, in tools like the data lakes in Microsoft Fabric and the enterprise content stored in SharePoint.
Azure AI Agent Service builds on Azure’s infrastructure capabilities, adding support for private networks and your own storage. The intent is to take advantage of Azure’s existing certifications and regulatory approvals to quickly build AI tools to deliver compliant applications. This move should help enterprises adopt AI, using Azure AI Foundry to bring relevant stakeholders together and Azure AI Agent Services to apply the necessary controls—for both internal and external approvals.
Improving Azure’s AI infrastructure
As well as new software features, Azure is adding more AI-specific infrastructure tools. AI applications hosted in Azure Container Apps can now use serverless GPUs for inferencing, scaling Nvidia hardware to zero when not in use to help keep costs down. Other options improve container security to reduce the risks associated with using LLMs on sensitive data, whether it’s personally identifiable information or commercially sensitive data from line-of-business platforms.
Ignite is where Microsoft focuses on its business software, so it’s the right place to launch a developer product like Azure AI Foundry. Azure AI Foundry is designed to build AI into the complete software development life cycle, from design and evaluation to coding and operation, providing a common place for developers, AIops, data scientists, and business analysts to work together with the tools to build the next generation of AI applications.
With agentic AI apps, it’s clear that Microsoft thinks it’s time for enterprises to go beyond the chatbot and use AI to get the benefits of flexible, intelligent, business process automation. Building on Azure AI Foundry and Semantic Kernel, we’re able to deliver the context-aware long transaction applications we’ve wanted to build—ensuring that they’re both trustworthy and regulatory compliant.
{kind=link}
Kotlin for Java developers: Classes and coroutines 20 Nov 2024, 9:00 am
Java is one of the classic object-oriented languages, so classes and objects are of special interest to Java developers. Object-oriented programming gives you considerable power, particularly when it comes to structuring and organizing programs as they grow larger. That’s why most modern languages give you objects in one form or another.
On the other hand, defining and maintaining classes and their hierarchies can be complex, and it’s easy to get bogged down when programming with them. What’s needed is a compromise. Kotlin is one of the newer languages that works behind the scenes to simplify programming while still letting you access complexity when you need it.
How Kotlin simplifies classes
In my previous article, I showed an example of a class written in Kotlin. Here’s another:
data class StarWarsMovie(val title: String, val episode_id: Int, val release_date: String)
Believe it or not, this one line gives you a full-blown class. It is a data class, which provides common methods like equals and toString automatically. Otherwise, it acts just like any other class. This class models a Star Wars movie with the movie title, ID, and release date.
The thing to notice is that Kotlin reduces class creation down to the bare essence. In this example, all we provided was the class name and constructor arguments. Kotlin deduced everything else it needed based on the types and names of the arguments. A Kotlin class behaves just like a Java class, but without requiring that we write out the members explicitly.
Public members and methods
In Kotlin, members and methods are public by default, so we can create a class instance and directly access its properties:
val newHope = StarWarsMovie("A New Hope", 4, "1977-05-25")
println(newHope.id) // outputs “4”
It’s an interesting design difference between requiring a visibility declaration, as Java does, versus assuming public, as Kotlin does. This kind of streamlining makes for a simpler and faster language surface. On the flipside, if you want the safety of private members, Kotlin requires that you explicitly set that modifier.
To make one of the fields private, we could do this:
class StarWarsMovie(val title: String, private val episode_id: Int, val release_date: String)
println("test: " + newHope.episode_id) // Error
Function extensions
Another example of Kotlin’s dynamism is function extensions, or simply extensions. These let you add a function to an existing class or interface. This feature is well-known in the JavaScript world, but it really stands out in the context of Java-like classes. Here, we are adding a new method to our existing StarWarsMovie class:
fun StarWarsMovie.releaseYear(): Int {
val year = release_date.substring(0, 4)
return year.toInt()
}
val newHope = StarWarsMovie("A New Hope", 4, "1977-05-25")
val releaseYear = newHope.releaseYear()
println("The release year of A New Hope is $releaseYear")
In the above example, we’ve defined a new method on the class, called releaseYear(). Note that we defined it directly on the existing class: StarWarsMovie.releaseYear(). We can do this with our own classes, but also with classes imported from third-party libraries. The Kotlin documentation shows an example of adding a method to the standard library. (I’m a bit wary of this kind of monkey patching but it certainly shows Kotlin’s flexibility.)
Now, imagine we wanted StarWarsMovie to be a subclass of a Movie superclass. In Kotlin, we could do something like this:
open class Movie(val title: String, val releaseDate: String) {
open fun releaseYear(): Int {
val year = releaseDate.substring(0, 4) return year.toInt()
}
}
class StarWarsMovie(title: String, episodeId: Int, releaseDate: String) : Movie(title, releaseDate) {
val episodeId: Int = episodeId
}
The open keyword indicates that a class or function is available for subclassing or overriding. In Java terms, Kotlin classes are final by default. Default public members and default final classes could be interpreted as subtle encouragement to prefer composition over inheritance. In the preceding example, we used constructor-based declaration for both StarWarsMovie and Movie. The colon in : movie indicates extension, working similarly to Java’s extends keyword.
Making class declarations explicit
You also have the option to declare things more explicitly in Kotlin, more along the lines of Java:
class Movie {
var title: String = ""
var releaseDate: String = ""
constructor(title: String, releaseDate: String) {
this.title = title
this.releaseDate = releaseDate
}
fun releaseYear(): Int {
val year = releaseDate.substring(0, 4)
return year.toInt()
}
}
class StarWarsMovie(title: String, releaseDate: String, val episodeId: Int) : Movie(title, releaseDate) {
// ...
}
Here we’ve opened up the class, which to a Java developer is self-explanatory. The constructor is defined with the constructor keyword instead of the class name. This can be combined with the default constructor style I showed earlier if alternate constructors are needed:
class Movie(title: String, releaseDate: String) {
var title: String = title
var releaseDate: String = releaseDate
constructor(title: String) : this(title, "") {
println("Secondary constructor called")
}
}
In general, it’s pretty easy to mix and match Kotlin’s object-oriented syntaxes, opting for the simpler syntax when you can and expanding into the more detailed syntax when you must.
Associated with the notion of constructors, Kotlin provides an init keyword that lets you run code during object creation. Outside of init, only property declarations are allowed. Kotlin differentiating properties from logic during construction is different from Java:
class StarWarsMovie(title: String, episodeId: Int, releaseDate: String) : Movie(title, releaseDate) {
val episodeId: Int = episodeId
init { println("Made a new star wars movie: $episodeId") } // un-Java-like init block
}
Ad hoc class declarations
One of the most freeing of Kotlin’s improvements is the ability to declare types, classes, and functions ad hoc, wherever you are in the code. This makes it simpler to think, “I’m going to need a class here,” and immediately write one. You can then return to your overall task in the same spot and use the new class. Later, you can go back and refine the class and possibly extract it to its own file, just like you would in Java.
Singleton-style objects
Kotlin lets you define a singleton-style object with the object keyword:
object MovieDatabase {
private val movies = mutableListOf()
fun addMovie(movie: Movie) {
movies.add(movie)
}
fun getMovies(): List {
return movies.toList()
}
}
Objects like this can only be declared top-level, not nested inside other blocks.
A singleton means there’s only one instance globally for a given run of the program. This is a common pattern in Java and Java-based frameworks like Spring. You have references that you pass around, but they all refer to the same MovieDatabase:
val db = MovieDatabase;
db.addMovie(movie)
db.addMovie(starWarsMovie)
// some other remote part of your app:
println("Got the same instance: ${db.getMovies()}")
The point here is that everyone gets a handle to the same instance. If we run this code immediately, we’ll get ugly output:
Got the same instance: Movie@3b764bce StarWarsMovie@759ebb3d
Your first thought might be to make Movie a data class, to get the toString() method for free, but data classes are final. A better option is to add a simple toString ourselves:
open class Movie(val title: String, val releaseDate: String) {
override fun toString(): String {
return "Movie(title='$title', releaseYear=${releaseYear()})"
}
}
Now we’ll get nicer output:
Got the same instance: Movie(title='The Shawshank Redemption', releaseYear=1994) Movie(title='A New Hope', releaseYear=1977)
Concurrency and coroutines in Kotlin
Concurrency is another area where Kotlin brings interesting options to the table. Java has been very active lately in improving its concurrency model, and some of the improvements are inspired by Kotlin’s coroutines. Coroutines give you a different kind of access to threading. One of the mechanisms used is structured concurrency, which is now being added to Java.
Coroutines and structured concurrency keep your thread management in a synchronistic, declarative style. Here’s a simple example from Kotlin’s documentation:
import kotlinx.coroutines.*
fun main() = runBlocking { // this: CoroutineScope
launch { doWorld() }
println("Hello")
}
// this is your first suspending function
suspend fun doWorld() {
delay(1000L)
println("World!")
}
The suspend keyword indicates that the doWorld function can be suspended by the concurrency engine, meaning that method is non-blocking. You’ll notice the main function is set to the runBlocking function, which establishes a blocking CoroutineScope. All concurrent code must be declared inside a CoroutineScope.
The actual mechanism for launching a thread is the launch keyword, which is used by the main method to call doWorld.
Obviously, we are just scratching the surface of concurrency and coroutines in Kotlin, but these examples give you a sense of how coroutines work in relation to Java. As I mentioned, Java is actually moving closer to Kotlin in this area. Another point to note about Kotlin’s concurrency is the JVM’s introduction of virtual threads. This feature implies the possibility of using Kotlin’s coroutines with the JVM’s virtual threads.
Conclusion
Kotlin modifies some of Java’s rules to introduce more flexibility and improve areas where coding can become bogged down. Whereas Java code tends toward the rigorous and explicit, Kotlin leans towards flowing and conventional. The great thing is that Kotlin gives you this wonderfully expressive modern language that you can use right along with Java, in the JVM. I think most Java developers will appreciate what they can do with Kotlin.
{kind=link}
What is Rust? Safe, fast, and easy software development 20 Nov 2024, 9:00 am
A programming language can be fast, safe, or easy to write. As developers, we get to choose our priorities but we can only pick two. Programming languages that emphasize convenience and safety tend to be slow (like Python). Languages that emphasize performance tend to be difficult to use and quick to blow things up (like C and C++). That has been the state of software development for a good long time now.
Is it possible to deliver speed, safety, and ease of use in a single language? The Rust language, originally created by Graydon Hoare and currently sponsored by Google, Microsoft, Mozilla, Arm, and others, attempts to bring together these three attributes in one language. (Google’s Go language has similar ambitions, but Rust aims to make fewer concessions along the way.)
Rust is meant to be fast, safe, and reasonably easy to use. It’s also intended to be used widely, and not simply end up as a curiosity or an also-ran in the programming language sweepstakes. Good reasons abound for creating a language where safety sits on equal footing with speed and development power. After all, there’s a tremendous amount of software—some of it driving critical infrastructure—built with languages that did not put safety first.
Rust language advantages
Rust started as a Mozilla research project partly meant to reimplement key components of the Firefox browser. The project’s priorities were driven by the need to make better use of multicore processors in Firefox, and the sheer ubiquity of web browsers meant that they must be safe to use.
But it turns out all software needs to be fast and safe, not just browsers. So, Rust evolved from its origins as a browser component project into a full-blown language project.
This article is a quick look at the key characteristics that make Rust an increasingly popular language for developers seeking an alternative to the status quo. We’ll also consider some of the downsides to adopting Rust.
Rust is fast
Rust code compiles to native machine code across multiple platforms. Binaries are self-contained, with no external runtime apart from what the operating system might provide, and the generated code is meant to perform as well as comparable code written in C or C++.
Rust is memory-safe
Rust won’t compile programs that attempt unsafe memory usage.
In other languages, many classes of memory errors are discovered when a program is running. Rust’s syntax and language metaphors ensure that common memory-related problems in other languages—null or dangling pointers, data races, and so on—never make it into production. The Rust compiler flags those issues and forces them to be fixed before the program ever runs.
Rust features low-overhead memory management
Rust controls memory management via strict rules. Rust’s memory-management system is expressed in the language’s syntax through a metaphor called ownership. Any given value in the language can be “owned,” or held and manipulated, only by a single variable at a time. Every bit of memory in a Rust program is tracked and released automatically through the ownership metaphor.
The way ownership is transferred between objects is strictly governed by the compiler, so there are no surprises at runtime in the form of memory-allocation errors. The ownership approach also means that Rust does not require garbage-collected memory management, as in languages like Go or C#. (That also gives Rust another performance boost.)
Rust’s safety model is flexible
Rust lets you live dangerously, up to a point. Rust’s safeties can be partly suspended where you need to manipulate memory directly, such as dereferencing a raw pointer à la C/C++. The key word here is partly, because Rust’s memory safety operations can never be completely disabled. Even then, you almost never have to take off the seatbelts for common use cases, so the end result is software that’s safer by default.
Rust is cross-platform
Rust works on all three major platforms: Linux, Windows, and macOS. Others are supported beyond those three. If you want to cross-compile, or produce binaries for a different architecture or platform than the one you’re currently running, some additional work is involved. However, one of Rust’s general missions is to minimize the amount of heavy lifting needed for such work. Also, although Rust works on the majority of current platforms, its creators are not trying to have Rust compile everywhere—just on whatever platforms are popular, and wherever they don’t have to make unnecessary compromises to the language to do so.
Rust is easy to deploy
None of Rust’s safety and integrity features add up to much if they aren’t used. That’s why Rust’s developers and community have tried to make the language as useful and welcoming as possible to both newcomers and experienced developers.
Everything needed to produce Rust binaries comes in the same package. You only need external compilers like GCC if you are compiling other components outside the Rust ecosystem (such as a C library that you’re compiling from source). Windows users are not second-class citizens here, either; the Rust toolchain is as capable on Windows as it is on Linux and macOS.
Rust has powerful language features
Few developers want to start work in a new language if they find it has fewer or weaker features than the ones they’re already using. Rust’s native language features compare favorably to what languages like C++ have: Macros, generics, pattern matching, and composition (via “traits”) are all first-class citizens in Rust. Some features found in other languages, like inline asembler, are also available, albeit under Rust’s “unsafe” label.
Rust has a useful standard library
A part of Rust’s larger mission is to encourage C and C++ developers to use Rust instead of those languages whenever possible. But C and C++ users expect to have a decent standard library—they want to be able to use containers, collections, and iterators, perform string manipulations, manage processes and threading, perform network and file I/O, and so on. Rust does all that, and more, in its standard library. Because Rust is designed to be cross-platform, its standard library can contain only things that can be reliably ported across platforms. Platform-specific functions like Linux’s epoll have to be supported via functions in third-party libraries such as libc, mio, or tokio.
It is also possible to use Rust without its standard library. One common reason to do so is to build binaries that have no platform dependencies — e.g., an embedded system or an OS kernel.
Rust has many third-party libraries, or ‘crates’
A measure of a language’s utility is how much can be done with it thanks to third parties. Cargo, the official repository for Rust libraries (called “crates”) lists some 60,000-plus crates. A healthy number of them are API bindings to common libraries or frameworks, so Rust can be used as a viable language option with those frameworks. However, the Rust community does not yet supply detailed curation or ranking of crates based on their overall quality and utility, so you can’t tell what works well without trying things yourself or polling the community.
Rust has strong IDE support
Again, few developers want to embrace a language with little or no support in the IDE of their choice. That’s why the Rust team created the Rust Language Server, which provides live feedback from the Rust compiler to IDEs such as Microsoft Visual Studio Code.
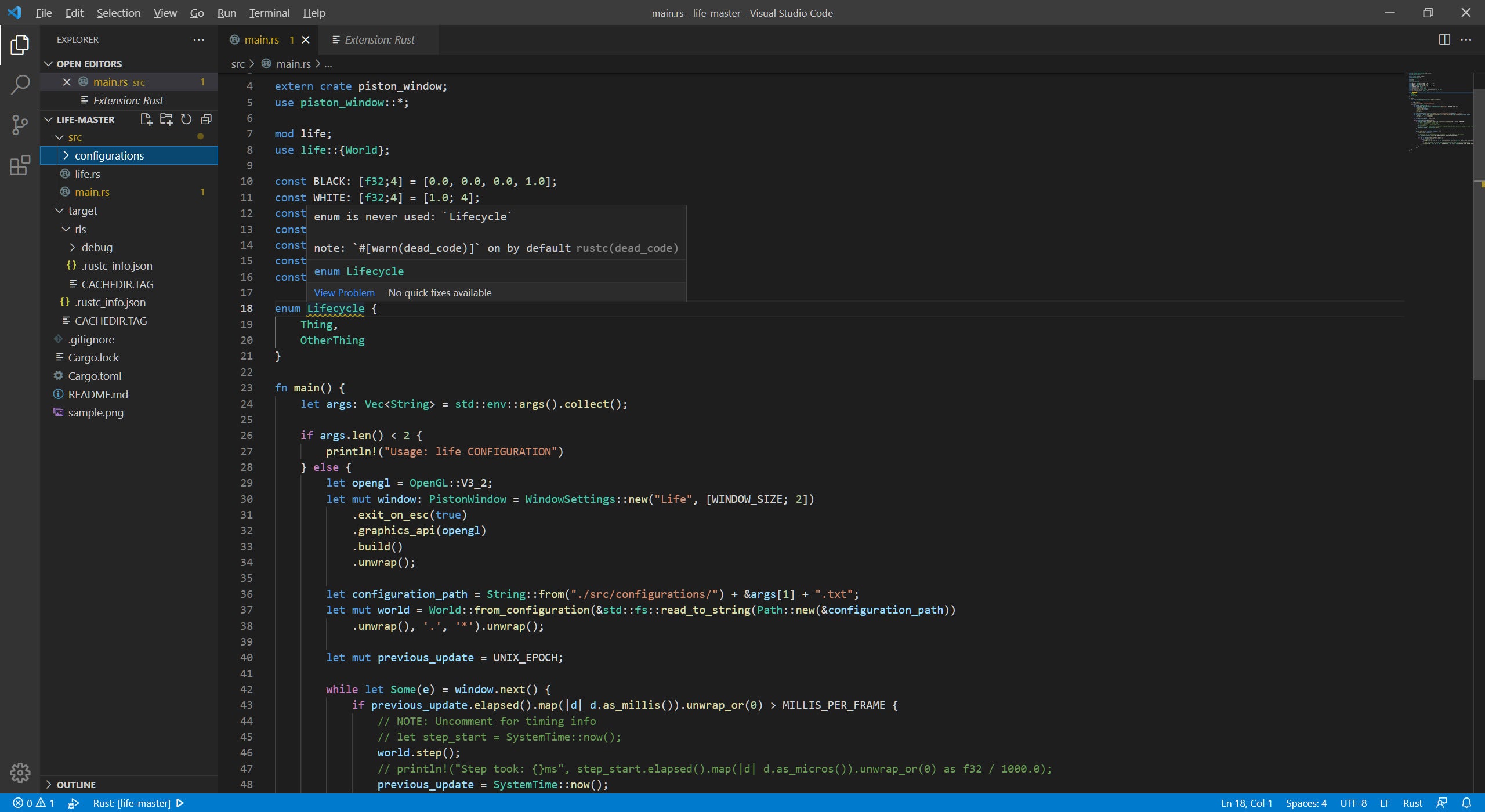
Live feedback in Visual Studio Code from the Rust Language Server. The Rust Language Server offers more than basic syntax checking; it also determines things like variable use.
Downsides of programming with Rust
Along with all of its attractive, powerful, and useful capabilities, Rust has its downsides. Some of these hurdles trip up new “rustaceans” (as Rust fans call each other) and old hands alike.
Rust is a young language
Rust is still a young language, having delivered its 1.0 version only in 2015. So, while much of the core language’s syntax and functionality has been hammered down, a great many other things around it are still fluid. Asynchronous operations, for example, are still a work in progress in Rust. Some parts of async are more mature than others, and many parts are provided via third-party components.
Rust is difficult to learn
If any one thing about Rust is most problematic, it’s how difficult it can be to grok Rust’s metaphors. Ownership, borrowing, and Rust’s other memory management conceits trip everyone up the first time. A common rite of passage for newbie Rust programmers is fighting the borrow checker, where they discover firsthand how meticulous the compiler is about keeping mutable and immutable things separate.
Rust is complex
Some of the difficulty of learning Rust comes from how its metaphors make for more verbose code, especially compared to other languages. For example, string concatenation in Rust isn’t always as straightforward as string1+string2. One object might be mutable and the other immutable. Rust is inclined to insist that the programmer spell out how to handle such things, rather than let the compiler guess.
Another example is how Rust and C/C++ work together. Much of the time, Rust is used to plug into existing libraries written in C or C++; few projects in C and C++ are rewritten from scratch in Rust. (And when they are, they tend to be rewritten incrementally.)
Rust is a systems language
Like C and C++, Rust can be used to write systems-level software, since it allows direct manipulation of memory. But for some jobs, that’s overkill. If you have a task that is mainly I/O-bound, or doesn’t need machine-level speed, Rust might be an ungainly choice. A Python script that takes five minutes to write and one second to execute is a better choice for the developer than a Rust program that takes half an hour to write and a hundredth of a second to run.
The future of Rust
The Rust team is conscious of many of its issues and is working to improve them. For example, to make it easier for Rust to work with C and C++, the Rust team is investigating whether to expand projects like bindgen, which automatically generates Rust bindings to C code. The team also has plans to make borrowing and lifetimes more flexible and easier to understand.
Still, Rust succeeds in its goal to provide a safe, concurrent, and practical systems language, in ways other languages don’t, and to do it in ways that complement how developers already work.
{kind=link}
Microsoft unveils imaging APIs for Windows Copilot Runtime 20 Nov 2024, 1:09 am
Microsoft’s Windows Copilot Runtime, which allows developers to integrate AI capabilities into Windows, is being fitted with AI-backed APIs for image processing. It will also gain access to Phi 3.5 Silica, a custom-built generative AI model for Copilot+ PCs.
Announced at this week’s Microsoft Ignite conference, the new Windows Copilot Runtime imaging APIs will be powered by on-device models that enable developers and ISVs to integrate AI within Windows applications securely and quickly, Microsoft said. Most of the APIs will be available in January through the Windows App SDK 1.7 experimental 2 Experimental release.
Developers will be able to bring AI capabilities into Windows apps via these APIs:
- Image description, providing a text description of an image.
- Image super resolution, increasing the fidelity of an image as well as upscaling the resolution of an image.
- Image segmentation, enabling the separation of foreground and background of an image, along with removing specific objects or regions within an image. Image editing or video editing apps will be able to incorporate background removal using this API, which is powered by the Segment Anything Model (SAM).
- Object erase, enabling erasing of unwanted objects from an image and blending the erased area with the remainder of the background.
- Optical character recognition (OCR), recognizing and extracting text present within an image.
Phi 3.5 Silica, built from the Phi series of models, will be included in the Windows Copilot Runtime out of the box. It will be custom-built for the Snapdragon X series neural processing unit (NPU) in Copilot+ PCs, enabling text intelligence capabilities such as text summarization, text completion, and text prediction, Microsoft said.
{kind=link}
Microsoft extends Entra ID to WSL, WinGet 19 Nov 2024, 9:37 pm
Microsoft has added new security features to Windows Subsystem for Linux (WSL) and the Windows Package Manager (WinGet), including integration with Microsoft Entra ID (formerly Active Directory) for identity-based access control. The goal is to enable IT admins to more effectively manage the deployment and use of these tools in enterprises.
The improvements were announced at the Microsoft Ignite conference.
For WSL, Microsoft Entra ID integration is in private preview. Entra ID integration will provide a “zero trust” experience for users accessing enterprise resources from within a WSL distribution, providing better security around passing Entra tokens and an automatic connection for Linux processes to use underlying Windows authentication, Microsoft said. Further, Intune device compliance integration with WSL, now generally available, provides IT admins with an interface to control WSL distribution and version usage in enterprises through conditional access.
[ Related: Microsoft Ignite 2024 news and insights ]
WSL also will have a new distribution architecture to provide a more efficient way for enterprise developers, IT professionals, and users to set up and customize WSL distributions while complying with enterprise security policies. IT professionals can build custom distributions by bundling together necessary applications, binaries, and tools, and distribute them to users. WSL distributions now can be installed through configurable source locations, separate from Microsoft Store. These features are to be previewed in the coming months.
For WinGet, a command line tool that allows users to install Windows apps, Entra ID integration is available in public preview. The integration allows IT professionals to manage WinGet access so that only authorized users within an enterprise can install software onto their devices. Also, WinGet now allows enterprise customers to download line-of-business apps from any WinGet source using the WinGet Download command. WinGet Download is now generally available.
{kind=link}
Microsoft rebrands Azure AI Studio to Azure AI Foundry 19 Nov 2024, 1:30 pm
Microsoft is packaging its Azure AI Studio and other updates into a new service — Azure AI Foundry in response to enterprises’ need to develop, run, and manage generative AI applications.
Launched at the company’s annual Ignite conference, Azure AI Foundry is being marketed as a “unified application platform in the age of AI,” akin to the Azure AI Studio, which was released in November last year and made generally available in May this year.
[ Related: Microsoft Ignite 2024 news and insights ]
Azure AI Studio was developed and marketed by Microsoft as a generative AI application development platform with support for model filtering, model benchmarking, prompt engineering, retrieval augmented generation, agent building, AI safety guardrails, and to an extent low-code development.
Azure AI Studio also has speech, vision, and language capabilities to help build apps with support for voice and the ability to read text and images in multiple languages.
However, Azure AI Studio is not to be confused with the Microsoft Copilot Studio, which experts claim is a “2nd-floor level low-code tool for customizing chatbots.”
What is Azure AI Foundry?
The new Azure AI Foundry service comprises the Azure AI Foundry portal, which was earlier the Azure AI Studio, the Azure AI Foundry software development kit (SDK), Azure AI Agents, and pre-built app templates along with some tools for AI-based application development.
The Azure AI Foundry SDK, in turn, comprises the AI toolchain that makes Azure AI services and capabilities accessible from tools such as GitHub and Visual Studio, the company said in a statement, adding that these tools allow developers to build an application that can be integrated with another program.
Microsoft said it has morphed the Azure AI Studio into the Azure AI Foundry portal along with new updates that help in the development, running, and management of AI-based applications.
Azure AI Foundry would act like a management console, akin to the AWS Management Console that lets enterprise users access different tools including a cost estimator, usage checker, billing console, and other core services offered as part of its cloud services.
Inside the Azure AI Foundry portal, Microsoft said it was introducing a new management center experience that brings subscription information, such as connected resources, access privileges, and quota usage.
“This can save development teams valuable time and facilitate easier security and compliance workflows throughout the entire AI lifecycle,” the company said in a statement.
Other updates include the addition of new specialized industry-specific generative AI models from companies including Bayer, Sight Machine, Rockwell Automation, Saifr/Fidelity Labs, and Paige.ai targeting the healthcare, finance, IT, and the manufacturing sector among others.
What is the new Azure AI Agent service?
The new Azure AI Agent service, which comes packaged with Azure AI Foundry, is an upgrade over the agents available inside Azure AI Studio and falls into the genre of autonomous AI agents that Microsoft showcased last month.
Autonomous AI agents, otherwise known as agentic AI, can perform tasks without human intervention and Microsoft’s new agents, according to the company, are targeted at automating business processes.
However, the company pointed out that the agents will ask its users for a final review or call for them to take action before it completes the process. This process has been put in place to ensure that these autonomous agents operate responsibly, it explained.
In contrast, the agents bundled inside Azure AI Studio were conversational retrieval agents, which is essentially an expansion from the idea of conversational large language models (LLMs) combined with tools, code, embeddings, and vector stores. Other updates that are packaged with Azure AI Foundry includes updates to Azure AI Search, which now includes a generative query engine; migrated features from Azure OpenAI service, simplified navigation, and more detailed documentation.
{kind=link}
A GRC framework for securing generative AI 19 Nov 2024, 9:00 am
From automating workflows to unlocking new insights, generative AI models like OpenAI’s GPT-4 are already delivering value in enterprises across every industry. But with this power comes a critical challenge for organizations: How do they secure and manage the expanding ecosystem of AI applications that touch sensitive business data? Generative AI solutions are popping up everywhere—embedded in platforms, integrated into products, and accessible via public tools.
In this article, we introduce a practical framework for categorizing and securing generative AI applications, giving businesses the clarity they need to govern AI interactions, mitigate risk, and stay compliant in today’s rapidly evolving technology landscape.
Types of AI applications and their impact on enterprise security
AI applications differ significantly in how they interact with data and integrate into enterprise environments, making categorization essential for organizations aiming to evaluate risk and enforce governance controls. Broadly, there are three main types of generative AI applications that enterprises need to focus on, each presenting unique challenges and considerations.
Web-based AI tools – Web-based AI products, such as OpenAI’s ChatGPT, Google’s Gemini, and Anthropic’s Claude, are widely accessible via the web and are often used by employees for tasks ranging from content generation to research and summarization. The open and public nature of these tools presents a significant risk: Data shared with them is processed outside the organization’s control, which can lead to the exposure of proprietary or sensitive information. A key question for enterprises is how to monitor and restrict access to these tools, and whether data being shared is adequately controlled. OpenAI’s enterprise features, for instance, provide some security measures for users, but these may not fully mitigate the risks associated with public models.
AI embedded in operating systems – Embedded AI products, such as Microsoft Copilot and the AI features within Google Workspace or Office 365, are tightly integrated into the systems employees already use daily. These embedded tools offer seamless access to AI-powered functionality without needing to switch platforms. However, deep integration poses a challenge for security, as it becomes difficult to delineate safe interactions from interactions that may expose sensitive data. The crucial consideration here is whether data processed by these AI tools adheres to data privacy laws, and what controls are in place to limit access to sensitive information. Microsoft’s Copilot security protocols offer some reassurance but require careful scrutiny in the context of enterprise use.
AI integrated into enterprise products – Integrated AI products, like Salesforce Einstein, Oracle AI, and IBM Watson, tend to be embedded within specialized software tailored for specific business functions, such as customer relationship management or supply chain management. While these proprietary AI models may reduce exposure compared to public tools, organizations still need to understand the data flows within these systems and the security measures in place. The focus here should be on whether the AI model is trained on generalized data or tailored specifically for the organization’s industry, and what guarantees are provided around data security. IBM Watson, for instance, outlines specific measures for securing AI-integrated enterprise products, but enterprises must remain vigilant in evaluating these claims.
Classifying AI applications for risk management
Understanding the three broad categories of AI applications is just the beginning. To effectively manage risk and governance, further classification is essential. By evaluating key characteristics such as the provider, hosting location, data flow, model type, and specificity, enterprises can build a more nuanced approach to securing AI interactions.
A crucial factor in this deeper classification is the provider of the AI model. Public AI models, like OpenAI’s GPT and Google’s Gemini, are accessible to everyone, but with this accessibility comes less control over data security and greater uncertainty around how sensitive information is handled. In contrast, private AI models, often integrated into enterprise solutions, offer more control and customization. However, these private models aren’t without risk. They must still be scrutinized for potential third-party vulnerabilities, as highlighted by PwC in their analysis of AI adoption across industries.
Another key aspect is the hosting location of the AI models—whether they are hosted on premises or in the cloud. Cloud-hosted models, while offering scalability and ease of access, introduce additional challenges around data residency, sovereignty, and compliance. Particularly when these models are hosted in jurisdictions with differing regulatory environments, enterprises need to ensure that their data governance strategies account for these variations. NIST’s AI Risk Management Framework provides valuable guidance on managing these hosting-related risks.
The data storage and flow of an AI application are equally critical considerations. Where the data is stored—whether in a general-purpose cloud or on a secure internal server—can significantly impact an organization’s ability to comply with regulations such as GDPR, CCPA, or industry-specific laws like HIPAA. Understanding the path that data takes from input to processing to storage is key to maintaining compliance and ensuring that sensitive information remains secure. The OECD AI Principles offer useful guidelines for maintaining strong data governance in the context of AI usage.
The model type also must be considered when assessing risk. Public models, such as GPT-4, are powerful but introduce a degree of uncertainty due to their general nature and the open-source nature of the data they are trained on. Private models, tailored specifically for enterprise use, may offer a higher level of control but still require robust monitoring to ensure security. OpenAI’s research on GPT-4, for instance, illustrates both the advancements and potential security challenges associated with public AI models.
Finally, model training has important risk implications. Distinguishing between generalized AI and industry-specific AI can help in assessing the level of inherent risk and regulatory compliance. Generalized AI models, like OpenAI’s GPT, are designed to handle a broad array of tasks, which can make it harder to predict how they will interact with specific types of sensitive data. On the other hand, industry-specific AI models, such as IBM Watson Health, are tailored to meet the particular needs and regulatory requirements of sectors like healthcare or financial services. While these specialized models may come with built-in compliance features, enterprises must still evaluate their suitability for all potential use cases and ensure that protections are comprehensive across the board.
Establishing a governance framework for AI interactions
Classifying AI applications is the foundation for creating a governance structure that ensures AI tools are used safely within an enterprise. Here are five key components to build into this governance framework:
- Access control: Who in the organization can access different types of AI tools? This includes setting role-based access policies that limit the use of AI applications to authorized personnel.
Reference: Microsoft Security Best Practices outline strategies for access control in AI environments. - Data sensitivity mapping: Align AI applications with data classification frameworks to ensure that sensitive data isn’t being fed into public AI models without the appropriate controls in place.
Reference: GDPR Compliance Guidelines provide frameworks for data sensitivity mapping. - Regulatory compliance: Make sure the organization’s use of AI tools complies with industry-specific regulations (e.g., GDPR, HIPAA) as well as corporate data governance policies.
Reference: OECD AI Principles offer guidelines for ensuring regulatory compliance in AI deployments. - Auditing and monitoring: Continual auditing of AI tool usage is essential for spotting unauthorized access or inappropriate data usage. Monitoring can help identify violations in real-time and allow for corrective action.
Reference: NIST AI Risk Management Framework emphasizes the importance of auditing and monitoring in AI systems. - Incident response planning: Create incident response protocols specifically for AI-related data leaks or security incidents, ensuring rapid containment and investigation when issues arise.
Reference: AI Incident Database provides examples and guidelines for responding to AI-related security incidents.
Example: Classifying OpenAI GPT and IBM Watson Health
Let’s classify OpenAI ChatGPT and IBM Watson Health for risk management according to the characteristics we outlined above.
| Model | OpenAI GPT | IBM Watson Health |
| Provider | OpenAI | IBM |
| Hosting location | Cloud-hosted AI model (Azure) | Cloud-hosted AI model (IBM Cloud) |
| Data storage and flow | External data processing | Internal data processing |
| Model type | General public model | Industry-specific public model (healthcare) |
| Model training | Public knowledge, generalized | Industry-specific model training |
Now that we have the classifications, let’s overlay our governance framework.
| Model | OpenAI ChatGPT | IBM Watson Health |
| Access control | ChatGPT, being a general-purpose, cloud-hosted AI, must have strict access controls. Role-based access should restrict its use to employees working in non-sensitive areas (e.g., content creation, research). Employees handling sensitive or proprietary information should have limited access to prevent accidental data exposure. | IBM Watson Health is a highly specialized AI model tailored for healthcare, so access must be limited to healthcare professionals or staff authorized to handle sensitive medical data (PHI). Fine-grained role-based access control should ensure only those with explicit needs can use Watson Health. |
| Data sensitivity mapping | ChatGPT should be classified under “high-risk” for sensitive data processing due to its public, external data handling nature. Enterprises should map its use to less sensitive data (e.g., marketing or general information) and prevent interaction with customer PII or confidential business data. | Because Watson Health is designed to handle sensitive data (e.g., patient records, PHI), it must align with healthcare-specific data classification systems. All data processed should be marked as “highly sensitive” under classification frameworks like HIPAA and stringent safeguards must be in place. |
| Regulatory compliance | ChatGPT may struggle to meet strict regulatory standards like GDPR or HIPAA, as it’s not inherently compliant for handling highly sensitive or regulated data. Organizations must ensure that employees do not feed it information governed by strict data privacy laws. | Watson Health is designed to comply with industry regulations like HIPAA for healthcare and HITRUST for data security. However, enterprises still need to ensure that their specific deployment configurations are aligned with these standards, particularly regarding how data is stored and processed. |
| Auditing and monitoring | Continuous monitoring of interactions with ChatGPT is crucial, especially to track the data that employees share with the model. Logging all interactions can help identify policy violations or risky data-sharing practices. | Given its role in handling sensitive healthcare data, Watson Health requires continuous, real-time auditing and monitoring to detect potential unauthorized access or data breaches. Logs must be securely stored and routinely reviewed for compliance violations. |
| Incident response planning | Given ChatGPT’s general-purpose nature and external hosting, a specific incident response plan should be developed to address potential data leaks or unauthorized use of the model. If sensitive information is mistakenly shared, the incident must be investigated swiftly. | In case of a data breach or PHI exposure, Watson Health must have a healthcare-specific incident response plan. Rapid containment, remediation, and reporting (including notifications under HIPAA’s breach notification rule) are critical. |
Reducing AI risks through AI governance
As AI technology advances, it brings both transformative opportunities and unprecedented risks. For enterprises, the challenge is no longer whether to adopt AI, but how to govern AI responsibly, balancing innovation against security, privacy, and regulatory compliance.
By systematically categorizing generative AI applications—evaluating the provider, hosting environment, data flow, and industry specificity—organizations can build a tailored governance framework that strengthens their defenses against AI-related vulnerabilities. This structured approach enables enterprises to anticipate risks, enforce robust access controls, protect sensitive data, and maintain regulatory compliance across global jurisdictions.
The future of enterprise AI is about more than just deploying the latest models; it’s about embedding AI governance deeply into the fabric of the organization. Enterprises that take a proactive, comprehensive approach will not only safeguard their business against potential threats but also unlock AI’s full potential to drive innovation, efficiency, and competitive advantage in a secure and compliant manner.
Trevor Welsh is VP of products at WitnessAI.
—
Generative AI Insights provides a venue for technology leaders—including vendors and other outside contributors—to explore and discuss the challenges and opportunities of generative artificial intelligence. The selection is wide-ranging, from technology deep dives to case studies to expert opinion, but also subjective, based on our judgment of which topics and treatments will best serve InfoWorld’s technically sophisticated audience. InfoWorld does not accept marketing collateral for publication and reserves the right to edit all contributed content. Contact doug_dineley@foundryco.com.
{kind=link}
Succeeding with observability in the cloud 19 Nov 2024, 9:00 am
In its 2024 report, Splunk breaks down observability practices into four stages: foundational visibility, guided insights, proactive response, and unified workflows. Based on that, it classifies companies into four stages of observability maturity: beginning, emerging, evolving, and leading.
Splunk found that just 11% of organizations in the study have reached that final stage, and only 8% in the United Kingdom, suggesting that British businesses need to catch up to other countries regarding observability.
Observability versus monitoring
Keep in mind that Splunk is not a disinterested third party; it sells observability tools. I’m not saying they are spinning their statistics, but you’ll never hear a cloud observability company say that cloud observability is not an issue. As always, you need to consider the source to decide if their analysis has some wisdom. In this case, it does.
Observability is the ability to understand what is happening inside a system based on the external data it generates, such as logs, metrics, and traces. This data offers insights into the system’s internal state without directly interacting with it.
In the rapidly evolving world of cloud computing, observability has emerged as a critical asset for organizations navigating the complexities of cloud ecosystems. Cloud architectures have become increasingly dynamic and diverse. Multicloud deployments that span multiple cloud providers and on-premises environments have made gaining meaningful insights into system behavior not just advantageous but essential.
Observability is distinct from traditional monitoring and transcends mere reactive metrics and static dashboards. Monitoring often involves passively consuming information to assess system states. Observability takes an integrative and proactive approach to evaluate the holistic state of systems. It leverages the vast array of data, enabling IT teams to understand current system conditions, anticipate future states, and optimize performance accordingly.
Complexity makes observability a necessary evil
The complexity of modern cloud environments amplifies the need for robust observability. Cloud applications today are built upon microservices, RESTful APIs, and containers, often spanning multicloud and hybrid architectures. This interconnectivity and distribution introduce layers of complexity that traditional monitoring paradigms struggle to capture. Observability addresses this by utilizing advanced analytics, artificial intelligence, and machine learning to analyze real-time logs, traces, and metrics, effectively transforming operational data into actionable insights.
One of observability’s core strengths is its capacity to provide a continuous understanding of system operations, enabling proactive management instead of waiting for failures to manifest. Observability empowers teams to identify potential issues before they escalate, shifting from a reactive troubleshooting stance to a proactive optimization mindset. This capability is crucial in environments where systems must scale instantly to accommodate fluctuating demands while maintaining uninterrupted service.
The significance of observability also lies in its alignment with modern operations practices, such as devops, where continuous integration and continuous delivery demand rapid feedback and adaptation. Observability supports these practices by offering real-time insights into application performance and infrastructure health, allowing development and operations teams to collaborate effectively in maintaining system reliability and agility.
The steps to observability success
The path to effective observability travels through a landscape of complex dependencies, distributed systems, and rapidly changing technologies. To effectively implement observability for their cloud deployments, enterprises should consider the following actions:
- Cultivate a culture that prioritizes observability as a fundamental part of the development and operations processes. This involves recognizing the value of data-driven insights for optimizing performance and reliability.
- Deploy robust observability tools that can collect, analyze, and visualize data from logs, metrics, and traces across all cloud infrastructure components. Ensure these tools integrate seamlessly with existing systems and support multicloud environments.
- Leverage artificial intelligence and machine learning technologies to process large volumes of data and identify patterns or anomalies that could indicate potential issues. A proactive approach can help preempt problems before they impact users.
- Share insights and dashboards to encourage collaboration between development, operations, and business teams. This alignment helps rapidly address issues and improves overall system performance.
- Gain visibility into the entire application stack, from infrastructure to user experience. With a comprehensive view, you can understand how applications perform in real-world scenarios.
- Assess observability practices and tools regularly to ensure they meet evolving business needs. Stay updated with the latest advancements in observability technologies and methodologies to continually enhance capabilities.
- Equip teams with the necessary skills and knowledge to effectively utilize observability tools. Investing in employees can lead to better analysis, troubleshooting, and system optimization.
By taking these steps, enterprises can harness the full power of observability, leading to improved system reliability, faster incident response, and a more robust overall cloud strategy. This is way more complex than the current studies will lead you to believe, so you’re going to have to make some strides on your own.
{kind=link}
How to transform your architecture review board 19 Nov 2024, 9:00 am
I recall my angst about my first visit to an architecture review board (ARB), where a team of enterprise architects reviewed plans for new systems and application architectures. My presentation was required to follow a template and be reviewed by the board’s infrastructure and security leads prior to the presentation.
The corporate CIO selected and procured the technology platforms, so I didn’t expect any issues with using them. However, my teams were still learning about these technologies and the business requirements. At best, we had a conceptual architecture that would go through our agile development process to be refined and improved upon.
Our architecture was approved, but acclimating enterprise architects to a more agile approach to evolving the architecture required some creativity. I tell a longer version of this story in my book, Digital Trailblazer.
Architecture review boards are out of step
To this day, I shiver when I hear leaders speak about their architecture review boards and the process of presenting to them. To be clear, I believe these boards are important, but their missions, processes, and tools must be modernized for today’s faster and more agile development processes. ARBs and enterprise architects also have many opportunities to uplift digital transformation by weighing in on implantation tradeoffs and establishing which non-functional requirements are essential for specific initiatives.
“The role of an architecture review board once was much more autocratic, led by a small group that made decisions for the larger organization under a ‘one-size-fits-all’ philosophy,” says Dalan Winbush, CIO of Quickbase. The democratization of software, particularly through low-code/no-code, agile, and AI technologies, is changing the ARB’s role, said Winbush. Architecture review boards are expected to be more collaborative and responsive, and the ARB’s role is “more expansive in considering governance, security, compliance, data management, connectivity, and collaboration, all in service of larger business goals,” he said. “The ARB’s responsibilities include ensuring the integrity of the application development process, data, and the overall IT infrastructure.”
The Open Group Architecture Framework (TOGAF) version 9.2, published in 2018, describes the role of cross-organization architecture board as overseeing the implementation of strategy. It identifies over 20 responsibilities such as establishing targets for component reuse, providing advice, and resolving conflicts. However, some of the responsibilities listed may cause devops leaders to cringe, such as “providing the basis for all decision-making with regard to the architectures.”
A modernized approach to architecture review boards should start with establishing a partnership, building trust, and seeking collaboration between business leaders, devops teams, and compliance functions. Everyone in the organization uses technology, and many leverage platforms that extend the boundaries of architecture.
Winbush suggests that devops teams must also extend their collaboration to include enterprise architects and review boards. “Don’t see ARBs as roadblocks, and treat them as a trusted team that provides much-needed insight to protect the team and the business,” he suggests.
Architecture review boards can be especially useful for setting guideposts to help teams and organizations navigate competing agendas like these:
- Faster innovation vs. safer compliance
- Experimentation vs. best practices
- Self-organization vs. reliable standards
Let’s look at three scenarios the highlight the role and potential of an enlightened architecture review board.
Innovate architectures and minimize technical debt
For organizations developing microservices, how are standards created to ensure usability, reliability, and ongoing support? How can organizations avoid creating point-solution services, undocumented solutions, and APIs without robust automated testing? Empowering too much autonomy can lead to technical debt and microservices that are hard to support.
Another area of complexity is when organizations support multiple CI/CD tools and empower devops teams to create, customize, and support their own CI/CID pipelines. Over time, the benefits of self-organization diminish, and the cost, complexity, and technical debt can reduce development velocity.
“Applications today are more complex than they were 20 years ago,” says Rob Reid, technology evangelist at Cockroach Labs. “Compare the complexities of managing a microservice architecture to a client-server architecture, and you see why sub-one-hour restoration is a growing pipe dream.
“Deployment pipelines are increasingly non-standard, and every team carefully crafts their own bespoke pipeline using modern tools,” adds Reid. “As teams and technology evolve, knowledge of these pipelines and technologies fades, along with our pipe dreams.”
ARBs can play a role in helping organizations avoid complexity by defining technical debt metrics, promoting self-organizing standards, and guiding devops teams on best practices.
Prioritize and simplify risk remediation
IT teams once captured risk logs in spreadsheets and scored them based on the likelihood of a risk occurrence and its business impact. They then used these scores to prioritize remediations. Today, capturing, prioritizing, and managing risk can be baked into agile development and IT management services with tools like risk register for Jira and Confluence and ServiceNow Risk Management.
However, integrated tools don’t solve the issue of assessing priorities and identifying solutions that minimize remediation costs. ARBs can play a critical role, sometimes acting as product managers over risk backlogs and other times as delivery leaders overseeing implementations.
“If properly empowered, the board should operate as a critical arbiter of the broader conversation about regulatory compliance, best practices, and the continually evolving state of the art to how that translates into the specific actions a technical team takes,” says Miles Ward, CTO of SADA. “It’s easy to look backward at a breach or a cost-overrun and point to broad guidance on how to avoid such a thing; it’s much harder to anticipate, prioritize, and drive to implementations that actually prevent negative outcomes. Companies that tackle the hard part will outperform those who do not.”
Amplify AI, automation, and observability
Devops teams reduce toil by automating the scaffolding processes, including CI/CD, infrastructure as code, and Kubernetes orchestration. Coding copilots enable development teams to prompt for code, while automation and AI agents help IT service managers provide better employee experiences when responding to incidents and requests.
How can ARBs continue to rely on presentations, spreadsheets, and manually created architecture diagrams as their primary communication tools when devops is well down the path of improving productivity using automation and AI?
“Architectural review boards remain important in agile environments but must evolve beyond manual processes, such as interviews with practitioners and conventional tools that hinder engineering velocity,” says Moti Rafalin, CEO and co-founder of vFunction. “To improve development and support innovation, ARBs should embrace AI-driven tools to visualize, document, and analyze architecture in real-time, streamline routine tasks, and govern app development to reduce complexity.”
One opportunity for ARBs is to institute observability standards and site reliability engineering tools. These two areas connect development teams with operational responsibilities, where standards, governance, and platforms provide long-term business value.
“Architectural observability and governance represent a paradigm shift, enabling proactive management of architecture and allowing architects to set guardrails for development to prevent microservices sprawl and resulting complexity,” adds Rafalin.
It’s time to rebrand your architecture review board
I recommend that IT organizations with ARBs rebrand them with a more inviting, open, and inclusive name that connotes collaboration and trust. Words like forum, hub, team, and even council are more inviting than the idea of having to appear in front of a board. The word review suggests a process that is reactionary and judgmental, whereas words like enablement, excellence, and growth suggest increased collaboration with business, devops, and data science teams.
I informally polled my network and the rebrand of “collaboration architecture hub” received the most votes. I like the sound of it. By modernizing their tools, practices, and mindset, enterprise architects participating in such hubs may find a more receptive audience and improve results.
{kind=link}
F# 9 adds nullable reference types 19 Nov 2024, 1:06 am
F# 9, the latest version of Microsoft’s open source functional language, has been released with support for nullable reference types and empty-bodied computation expressions. Standard library improvements also are featured, including random sampling functions.
F# 9 was released in conjunction with the .NET 9 software platform on November 12. Instructions on getting started with F# can be found at dotnet.microsoft.com.
With nullable reference types in F# 9, F# now has a type-safe way to deal with reference types that can have null as a valid value. While F# was designed to avoid null, it nevertheless can creep in with .NET libraries written in C#. F# 9 also introduces support for empty computation expressions. Writing an empty computation expression will result in a call to the computation expression builder’s Zero method. This is a more natural syntax compared to the previously available builder { () }, Microsoft said.
In the FSharp.Core standard library in F# 9, the List, Array, and Seq modules have new functions for random sampling and shuffling, making F# easier to use for common data science, machine learning, and other scenarios where randomness is needed. Also with the standard library, Shuffle functions return a new collection of the same type and size, with each item in a randomly mixed position. In another standard library improvement, developers now can use C# collection expressions to initialize F# lists and sets from C#.
F# also brings performance improvements. Equality checks now are faster and allocate less memory, and the compiler now generates optimized code for more instances of start..finish and start..step..finish expressions.
Other new features and improvements in F# 9:
- Hash directives now are allowed to take non-string arguments. Previously, hash directives for the compiler only allowed string arguments passed in quotes.
- The
#helpdirective in F# Interactive now shows documentation for a given object or function, which now can be passed without quotes. - New or improved diagnostic messages or more precise diagnostic locations are featured in F# 9, such as unions with duplicated fields and active pattern argument count mismatch.
- To align with a pattern in some .NET libraries, where extension methods are defined with the same names as intrinsic properties of a type, F# now resolves these extension methods instead of failing the type check.
{kind=link}
Akka distributed computing platform adds Java SDK 18 Nov 2024, 10:30 pm
Akka, formerly known as Lightbend, has released Akka 3, an update to the JVM-based distributed computing platform that adds a Java SDK as well as serverless and “bring your own cloud” deployment options.
Akka 3 and the company’s name change were announced November 15. Sign-ups to try out Akka can be done at the company website.
The SDK in Akka 3 combines high-level components, a local console, and an event debugger. The composable components, covering endpoints, entities, streaming consumers, workflows, views, and timers, make it easy to build responsive, elastic, and resilient cloud applications, Akka said. While Akka libraries have supported both the Scala and Java languages for many years, the new SDK is based on Java. Akka believes the SDK is simple enough that most engineers, regardless of their language expertise, will be productive with Akka within one day, a company spokesman said.
Deployment options now include serverless, with Akka running the user’s apps in Akka’s cloud, and “bring your own cloud,” with users supplying their own AWS, Microsoft Azure, or Google Cloud cloud instances and Akka bringing the control plane, a cost profile, and managed infrastructure services. In early-2025, the company plans to roll out a self-hosted option for running Akka apps wherever desired, either on-premises or in private or a hybrid cloud.
For cloud deployments, Akka has focused on providing more flexibility regarding how an application is deployed and replicated, supporting single-region/pinned, multi-region/read-replicated, and multi-region/write-replicated topologies. Innovations in Akka 3 include an application runtime with multi-master replication, where each service instance runs in multiple locations, and a PaaS that migrates across hyperscalers, with operations able to stretch an application across multiple clouds and migrate an app from one cloud to another with no downtime or disruption.
Akka enables development of applications that are primarily event-driven. The platform provides libraries, components, sandboxes, build packs, and a cloud runtime, the company said.
{kind=link}
The dirty little secret of open source contributions 18 Nov 2024, 9:00 am
“Nobody cares if you contribute.” That’s what a Postgres friend said to me during lunch at KubeCon when I suggested that hiring Postgres contributors could be a selling point for customers. His comment surprised me because for years I’ve believed the open source dogma that contributions somehow qualified developers and vendors to disproportionately profit from projects. This, despite the overwhelming evidence to the contrary.
For example, no one has benefited more from open source than AWS but, relatively speaking, no one has contributed less. AWS has started to change, which I’ve celebrated. But after talking to my friend, I now wonder whether it matters at all. It may make employees feel better that their employer “gives back,” but it doesn’t seem to make the slightest difference to customers. Mostly. It’s worth talking about that “mostly.”
Make it easy
AWS has long billed itself as the best place to run open source software, and its customer success seems to support that statement. Open source has been central to AWS’ rise for nearly 20 years. Indeed, when I used to manage AWS’ open source strategy and marketing team, we ran a survey to uncover what customers cared about most in open source. Was it contributions or something else? Contributions made the list, but the number one determinant of open source “leadership,” according to developer respondents, was making it “easy to deploy my preferred open source software in the cloud.”
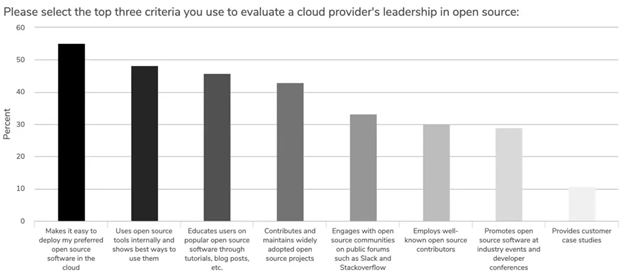
AWS
Enterprises, in other words, have a limited amount of time; they prefer vendors who remove the burden of managing their own open source software deployments, regardless of whether those same vendors are active contributors to the projects in question. This particular survey didn’t involve AWS customers and, indeed, I’m sure the results would be the same if you asked developers that use Microsoft Azure, Google Cloud, or any other cloud service. As much as you or I may think contributions to open source matter, customers just want to get stuff done as quickly as possible, for the lowest cost.
And yet there’s still an argument to be made for contributing to open source projects.
Contributions are part of the product
Back to my Postgres friend. Although he said customers may not care that so-and-so maintainer works for his company, having key contributors does enable his company to deliver excellent support to customers. In a community-run project such as Postgres or Linux, that doesn’t mean a particular employer gets to dictate road map, accelerate bug fixes, etc., but it does mean that they influence the road map. More importantly, it means they understand the code and the community around it and are thus better positioned to know how to weave short-term customer fixes into the main project without taking on technical debt. It also means, more simply, that they understand how to support a customer’s use of the code because they know that code intimately, in ways an interloping outsider simply doesn’t.
Additionally, though this happens rarely, should a company see a need to fork the project for long-term customer welfare, having core contributors and maintainers positions them to succeed with a fork. This is one reason AWS has a much greater chance of success with the Redis fork, Valkey. AWS has long employed one of Redis’ core maintainers, Madelyn Olson. Again, forks rarely happen, but contributing to an open source project is a solid insurance policy for a vendor’s customers. Is this something to market to customers? No. It’s behind-the-scenes work that ultimately creates a better product, but “we contribute” isn’t a product feature.
{kind=link}
Spin 3.0 supports polyglot development using Wasm components 18 Nov 2024, 9:00 am
Fermyon has released Spin 3.0, a major update to its open source developer tool for building serverless WebAssembly applications. The new release introduces polyglot programming to ease development.
The update to Fermyon’s Spin framework was introduced November 11. Installation instructions can be found on developer.fermyon.com.
Spin 3.0 introduces a workflow for polyglot programming that leverages component dependencies. This functionality is intended to make it seamless to perform tasks such as writing a library for a compute-intensive task in Rust and using it as a dependency in a JavaScript application. Component dependencies can be stored, discovered, and fetched from OCI registries, giving developers an experience akin to npm, NuGet, or crates.io but for Wasm, Fermyon said.
Spin 3.0 also includes an experimental flag, spin up --component-id, that lets developers specify which components to run from a Spin application, and it features deeper integration with WASI (WebAssembly System Interface) standards Spin 3.0, bringing support for the WASI Key-Value and WASI Config APIs. This support is a step toward bringing into Spin WASI cloud core, a WASI proposal for standardizing a set of APIs that applications can use to interact with a common set of cloud services.
Spin 3.0 also introduces support for OpenTelemetry (OTel) observability in Spin applications, enabling Spin application observability with popular tools such as Grafana, Jaegar, and Prometheus.
Finally, the release also features a major refactor of Spin internals with a feature called Spin Factors, where a “factor” encapsulates a host functionality feature. Spin Factors allow the Spin runtime to be more modular, Fermyon said.
Spin is positioned as a framework for building and running fast, secure, and composable cloud-based microservices with WebAssembly. Spin 3.0 follows Spin 2.0, introduced a year ago and focused on the developer experience and runtime performance. Spin 1.0 arrived in March 2022.
{kind=link}
Designing the APIs that accidentally power businesses 18 Nov 2024, 9:00 am
In the last decade, every web application developer has become an API designer. But most organizations do not think of developers as API designers, nor do they think about APIs as a product of design — to the detriment of their developers’ productivity. With the rise of AI, there are more APIs than ever before, making this problem even worse.
In this article, I’ll talk about the often-neglected internal APIs that, more and more, accidentally power businesses and how organizations can get back on top of these APIs.
The (internal) APIs that accidentally power businesses
The APIs that often get attention are the APIs that organizations have intentionally built their businesses on. These are APIs like the Stripe API, the Twilio API, and the Instagram API — APIs that are crucial to companies’ product and go-to-market strategies. These APIs start with well-reviewed designs and go through many iterations of polish, curation, and documentation before they reach their consumer, the public.
Then there are the APIs that organizations have accidentally built their businesses on:
- Front-end and back-end APIs. The rise of RESTful API design since the early 2000s means that web application front ends primarily talk to back ends via APIs.
- Cross-service APIs. The rise of service-oriented architectures since the early 2000s means that software organizations are structured such that each team owns a set of services. These teams operate in an increasingly decentralized way, with individual teams designing their own APIs, rather than a small number of architects designing all APIs in a top-down way.
There are often more of these kinds of APIs than external-facing APIs. These internal APIs are often designed and owned entirely by developers.
Why design matters for internal APIs
Okay, you might wonder. What does it matter that developers are designing APIs that external users have never seen? Product managers and business owners never dug into the code, so do they really need to dig into internal APIs?
The issue at hand is that developer-driven design decisions affect both the ability to deliver a good user experience and the velocity of development (and thus the nimbleness of the business). And there is a tension between these two concerns.
From the perspective of an API user, the ideal API design has the most general possible functions. For instance, if you’re using a bank API, you ideally want there to be only one function for getting the balance for a user, one function for changing the balance, etc. If there are dozens of functions to call to get a bank balance, it becomes much easier to call the wrong one!
From the perspective of a developer, however, the easiest API to build for is the most specific. This is because the more specific a function is, the more a developer can optimize. For instance, the way to build the fastest possible banking app is to have the app back end send exactly the right information the app front end needs and no more. Internal APIs bias towards performance, meaning they are designed by the developer for ease of optimization, rather than for ease of consumption.
In the absence of other forces, developers will bias towards delivering a good immediate user experience rather than towards longer-term development velocity, or even reuse of an API for platform purposes.
Harness the power of developer-driven design
There are two ways to look at the world of APIs we now live in. If we look at this world from the lens of top-down API design, we can bemoan the chaos and API sprawl that has befallen us and continue trying to get in control in a spec-first way.
But there’s a more empowering alternative, one where we accept the developer-driven nature of API design and embrace collaboration. API design does not have to be fully top-down, architect-driven, or bottom-up developer-determined. What if API design were, instead, a collaboration?
Here is one model of what collaborative API design looks like in a developer-first model:
- An API developer designs an internal API for a specific purpose, getting feedback from the immediate consumer and fellow API developer. These designs are not just static documentation but may be enhanced with richer information from tests or mocks.
- As the API gets more usage, the developer gets more feedback and updates the API.
- Previous versions of the API get stored and documented; the reasons for updating the API are clear to everyone.
- The API evolves in tandem with a “living design,” allowing developers to keep the API implementation optimized to the current use cases, allowing consumers to smoothly use the API for their needs, and allowing consumers and collaborators to give feedback as their needs change.
- Bonus: The living design gets updated automatically as the implementation updates, using real app behavior as the source of truth.
By making all software development API development, you unlock an immense amount of productivity — but only if it is as easy to share API designs as it is to share code and documents.
It is incredible how much faster software organizations can move when they empower developers to build APIs in a decentralized way. Fast, decentralized development does not require sacrificing organization or coordination. The key is productive collaboration.
Jean Yang is head of product at Postman.
—
New Tech Forum provides a venue for technology leaders—including vendors and other outside contributors—to explore and discuss emerging enterprise technology in unprecedented depth and breadth. The selection is subjective, based on our pick of the technologies we believe to be important and of greatest interest to InfoWorld readers. InfoWorld does not accept marketing collateral for publication and reserves the right to edit all contributed content. Send all inquiries to doug_dineley@foundryco.com.
{kind=link}
14 great preprocessors for developers who love to code 18 Nov 2024, 9:00 am
As much as we love them, programming languages can often feel like straitjackets. They’re a complex bundle of syntactic rules, and if we break them—even once—the compiler starts screaming out error messages. There are conventions to define every little thing, such as the best way to name variables or how to indent your code. The language designers claim these constraints are a feature, not a bug.
But programming languages don’t need to be that way. Over the years, clever developers have come up with sneaky and not so sneaky ways to write code in their own idiosyncratic styles. Preprocessors can bridge the gap, jumping into the pipeline before the code is compiled to fix all the strange twists and personal styles that keep coding fun.
Preprocessors aren’t new. Languages like C have relied on them for years. But lately they’ve been growing in popularity, as developers create more expressive ways to let programmers write software however they like. When it comes time to compile, all that unique style is quietly removed and replaced, so the final version fits the narrow rules of the language.
In the interest of programmers slipping out of the straitjacket, here’s our list of ways to preprocess your code. Included are language-specific preprocessors, ones that bridge the gap between data scientists and developers, and even one for converting American-style English to something more palatable to our colleagues across the pond.
LESS and SASS
The power and responsibilities given to CSS are now so great that we need a way to bring order to some of the more elaborate layouts seen on modern sites. Both LESS (Leaner CSS) and SASS (Syntactically Awesome StyleSheets) are preprocessors that let you behave more like a programmer by deploying variables and other functions to simplify a CSS layout. If your website design has a dominant color, you’ll only need to define it once. SASS is the more powerful of the two, with more complex options like loops. While it’s leaner, LESS is still powerful enough to get the job done. Either tool lets you bring a programmer’s touch and sensibility to cleaning up the seemingly endless list of CSS layout options.
AbsurdJS
Some people like consistency and prefer to work with one particular language. If you’re a fan of JavaScript and you want to use its power to craft your CSS, then AbsurdJS is the preprocessor for you. The letters JS are in the name, but the goal is CSS. With AbsurdJS, you can use the power of a programming concept like inheritance to produce elaborate CSS layouts. Like LESS and SASS, this is a preprocessor that lets you think like a programmer instead of a designer.
Bython
Some developers like using braces to define blocks of code. Some prefer hitting the spacebar and the tab key. Python was designed for the programmers who love a good indent. Now that it’s more powerful and ubiquitous, some of the curly-brace-loving crowd may want to use Python libraries and tools. Bython is a preprocessor that lets you keep your curly-braces and your Python libraries, too. You just code like you normally would and Bython does the rest. It will automatically replace your curly braces with indents, so you never have to hit the spacebar.
Pypreprocessor
The C language has long offered C coders the chance to make complex decisions about code with preprocessing statements like #ifdef, which turns big blocks of code on and off. Now Python programmers can do the same thing with Pypreprocessor, a dynamic library that lets you use flags and metavariables to make code disappear and reappear at will.
TypeScript
JavaScript was originally designed for web programmers who needed to add short blocks of code to websites that were mostly built from HTML. If you didn’t want to spell out the type of a variable, it was no big deal because the JavaScript code block was small and easy to understand. That’s changed, and now many developers build elaborate and very dynamic sites out of thousands and thousands of lines of JavaScript.
Given the range of JavaScript, some developers now want the assurance that comes from strongly typed code. TypeScript is the answer, and it’s an amazing compromise. Generic JavaScript continues to be acceptable to TypeScript, which means that all the type information you add is optional. TypeScript’s preprocessing stage double checks for errors when it can find them, then spits out something the generic JavaScript engine can process. Some of the most popular JavaScript frameworks, like Angular, now rely on TypeScript for strong typing.
CoffeeScript
For every Python programmer who yearns to be writing with a C-style syntax, there’s a JavaScript programmer who desires the freedom and simplicity of writing Python. CoffeeScript is the answer. There are now a number of variants like ToffeeScript, Civet, Storymatic, and CoffeeScript II: The Wrath of Khan, along with more than a dozen others. All these languages save us from the incredibly onerous task of lifting a right pinkie finger to press the semicolon key. They also offer neat features like asynchronous grammars and elaborate mechanisms for metaprogramming. The result is cleaner code with less punctuation, which is—in the eyes of CoffeeScript programmers, at least—much easier to read.
Handlebars and Pug
Modern code typically contains many blocks of text with messages for eventual human users. These are often filled with many insertions and customizations. Templating systems like Handlebars and Pug help to speed up writing these blocks of human readable text. There’s no need to write the low-level code required to glue together strings. You just write the text and the templating system handles the chore of patching together all the parts.
AWK
The Unix command-line tool is one of the simplest and most powerful tools for working with pure text. Named for its three original creators, Alfred V. Aho, Peter J. Weinberger, and Brian W. Kernighan, AWK links together a number of commands for extracting data from lines and sorting and filtering it. It is possible to build full reports using AWK. Programmers also use it to clean up raw data in the processing pipeline before the main program imports it.
Vapour
R is a powerful language that was largely created by statisticians, who generally think like mathematicians not computer programmers. That’s not a bad thing, but it can be a hurdle for using all the great libraries in R, which lack some of the great advances in programming design. Vapour is a preprocessor that lets R users think like programmers, specifically, programmers who love using type systems to catch bugs and enforce structure. Vapour’s developers say it’s still in an early alpha stage, so they may be adding new features and tweaking the syntax. The goal is to let the tool evolve quickly with the needs of users.
Spiffing
Not all English speakers use the language in the same way, particularly across continents and cultures. Spiffing (also see Spiffing) is a preprocessor that translates code written in American English to British English. It’s a bit of a goof, but that doesn’t mean it’s not useful or capable of bridging a cultural divide. If it catches on, maybe one day, developers will build out the preprocessor so that it converts the rather direct American-style diction into a more reserved British style. Instead of if-then statements, we could have perchance-otherwise syntax, for example.
Linting preprocessors
Not all preprocessors convert code. Some clean up after us and look for the bugs we’ve missed. The original Unix command-line tool, lint, has metastasized and now its functions are found as preprocessors in many language development stacks. These linting tools, or linters, fix formatting, enforce naming conventions, and even fix some syntactic and semantic errors. Some enforce rules that flag potential security flaws from bad logic. Popular versions include RuboCop for Ruby code, Pylint for Python, and ESLint for JavaScript (ECMAScript).
Preprocessors for documentation
Some preprocessors produce something other than runnable code. Tools like Sphinx, MkDocs, and Doxygen analyze your files and create an annotated and cross-referenced set of documentation files directly from code. These tools are designed to work with multiple languages but almost all the languages have their own official preprocessor. Popular examples include Javadoc, Rustdoc, Godoc, and JSDoc.
Preprocessors for integrated data reporting
Data scientists don’t just speak R language. They also write out complex data reports in a human language filled with charts, tables, and graphs created by R. Over the years, data scientists have created complex preprocessors for not only R but also LaTeX, the typesetting language. The scientist writes everything in R and human language, then the preprocessor splits it up, sending the computational instructions to R and the typesetting instructions to LaTeX. At the same time, it juggles the parts so the pictures produced by R end up in the right place in your document. LaTeX then folds them into the eventual PDF that’s produced from the human language parts of the file. It does all this while also organizing page references and illustration numbers to be consistent.
There are a variety of options with different strengths and advantages. R Markdown is a variation of common markdown that can also merge computational and data analysis. It can also merge in results from languages like Python or SQL to produce slides, documents, books, and websites. Knitr and its precursor Sweave are two closely aligned preprocessors that are both well-supported by Rstudio. For those who want to merge Python with LaTeX, there’s also Pweave. One day there may be a meta version that merges all of them into one big preprocessor.
Using AI for preprocessing
All preprocessors require some configuration. Why not just get an AI to do it? Some are already uploading their preprocessor to an LLM (large language model) and asking it to fix everything that’s wrong. In one example, some bean counters hit the roof after the developers told them that it would cost more than $1 million to rewrite their Agda compiler to make it current. Someone had the bright idea to just upload all 500+ files from their codebase to Anthropic’s Sonnet-3.5. And Voilà! The compiler was converted to TypeScript in the blink of an eye. The developers reported that most of the code ran fine with no intervention. The LLMs aren’t perfect, but they’re bringing us closer to a world where we can just wave our hands around and the machines do our bidding, like magic.
{kind=link}
Go language evolving for future hardware, AI workloads 16 Nov 2024, 12:17 am
The Go programming language having just turned 15 years old on November 10, proponents now are planning to adapt the Go language to large multicore systems, the latest vector and matrix hardware instructions, and the needs of AI workloads.
In a blog post on November 11, Austin Clements of the Go team said that, looking forward, Go would be evolved to better leverage the capabilities of current and future hardware. “In order to ensure Go continues to support high-performance, large-scale production workloads for the next 15 years, we need to adapt to large multicores, advanced instruction sets, and the growing importance of locality in increasingly non-uniform memory hierarchies,” Clements said. The Go 1.24 release will have a new map implementation that is more efficient on modern CPUs, and the Go team is prototyping new garbage collection algorithms that are designed for modern hardware. Some improvements will be in the form of APIs and tools that allow Go developers to make better use of modern hardware.
For AI, efforts are under way to make Go and AI better for each other, by enhancing Go capabilities in AI infrastructure, applications, and developer assistance. The goal is to make Go a “great” language for building production AI systems. The dependability of Go as a language for cloud infrastructure has made it a choice for LLM (large language model) infrastructure, Clements said. “For AI applications, we will continue building out first-class support for Go in popular AI SDKs, including LangChainGo and Genkit,” he said. Go developers already view the language as a good choice for running AI workloads.
Also on the roadmap are efforts to ensure that the Go standard library remains safe by default and by design. “This includes ongoing efforts to incorporate built-in, native support for FIPS-certified cryptography, so that FIPS crypto will be just a flag flip away for applications that need it,” Clements said.
In noting the 15th anniversary of Go’s initial open source release, Clements said the user base of the language has tripled in the past five years. Go ranked seventh in the November 2024 Tiobe index of programming language popularity, its highest ranking in the index ever. The most recent version, Go 1.23, was released in August, with faster PGO (profile-guided optimization) build times and the rollout of Go telemetry data.
{kind=link}
JDK 24: The new features in Java 24 15 Nov 2024, 9:00 am
In the wake of Java Development Kit (JDK) 23, which arrived September 17, work now focuses on the planned successor release, JDK 24, which has ballooned to 21 proposed features. The two most recent additions proposals would improve Java’s resistance to quantum computing attacks, by providing Java implementations of a quantum-resistant module-latticed-based digital signature algorithm and a quantum-resistant module-latticed-based key encapsulation mechanism.
Previously proposed features include removing the 32-bit x86 port; synchronizing virtual threads without pinning; simple source files and instance main methods; permanently disabling the security manager; module import declarations; an experimental version of compact headers; primitive types in patterns, instanceof, and switch; linking runtime images without JMODs; the generational Shenandoah garbage collector; scoped values; a key derivation function API; removal of the non-generational mode in the Z Garbage Collector; stream gatherers; a vector API; a class-file API; warnings to prepare developers for future restrictions on the use of JNI (Java Native Interface); and a late barrier expansion for the G1 garbage collector.
JDK 24 outdoes JDK 23, which listed 12 official features.
Due March 18, 2025, JDK 24 has been designated a non-long-term support (LTS) release. Like JDK 23, JDK 24 will receive only six months of premier-level support from Oracle. Early access builds of JDK 24 can be found at jdk.java.net.
The two features proposed for improving Java security through quantum-resistance include a quantum-resistant module-lattice-based key encapsulation mechanism (ML-KEM) and a quantum-resistant module-lattice-based digital signature algorithm (ML-DSA). ML-DSA would secure against future quantum computing attacks by using digital signatures to detect unauthorized modifications to data and to authenticate the identity of signatories. Key encapsulation mechanisms (KEMs) are used to secure symmetric keys over insecure communication channels using public key cryptography. Both features are designed to secure against future quantum computing attacks.
Flexible constructor bodies are in a third preview after being featured in JDK 22 and JDK 23, albeit with a different name in JDK 22, when the feature was called statements before super(…). The feature is intended to reimagine the role of constructors in the process of object initialization, letting developers more naturally place logic that they currently must factor into auxiliary static methods, auxiliary intermediate constructors, or constructor arguments.
Ahead-of-time class loading and linking aims at improving startup times by making classes of an application instantly available in a loaded and linked state, when the HotSpot Java virtual machine starts. This would be achieved by monitoring the application during one run and storing the loaded and linked forms of all classes in a cache for use in subsequent runs.
The Windows 32-bit x86 port was deprecated for removal in JDK 21 with the intent to remove it in a future release. Plans call for removing the source code and build support for the Windows 32-bit x86 port. Goals include removing all code paths that apply only to Windows 32-bit x86, ceasing all testing and development efforts targeting the Windows 32-bit x86 platform, and simplifying the JDK’s build and test infrastructure. The proposal states that Windows 10, the last Windows operating system to support 32-bit operation, will reach its end of life in October 2025.
Synchronizing virtual threads without pinning involves improving the scalability of Java code that uses synchronized methods and statements by arranging for virtual threads that block in such constructs to release their underlying platform for use by other threads. This would eliminate almost all cases of virtual threads being pinned to platform threads, which severely restricts the number of virtual threads available to handle an application workload.
A fourth preview of simple source files and instance main methods would evolve the Java language so beginners can write their first programs without needing to understand language features designed for large programs. The feature was previously previewed in JDK 21, JDK 22, and JDK 23. The goal is to allow beginning Java programmers to write streamlined declarations for single-class programs and then seamlessly expand their programs to use more advanced features as their skills grow.
Permanently disabling the security manager involves revising the Java platform specification so developers cannot enable the security manager, while other platform classes do not refer to it. The security manager has not been the primary means of securing client-side Java code for many years, has rarely been used to secure server-side code, and has been costly to maintain, the proposal states. The security manager was deprecated for removal in Java 17.
Module import declarations, previously previewed in JDK 23, enhance the Java programming language with the ability to succinctly import all of the packages exported by a module. This simplifies the reuse of modular libraries but does not require the importing of code to be a module itself.
Compact object headers would reduce the size of object headers in the HotSpot VM from between 96 and 128 bits down to 64 bits on 64-bit architectures. The goal of the proposed feature is to reduce heap size, improve deployment density, and increase data locality.
A second preview of primitive types in patterns, instanceof, and switch in JDK 24 would enhance pattern matching by allowing primitive types in all patterns and contexts. The feature also would extend instanceof and switch to work with all primitive types. The feature\’s goals include enabling uniform data exploration by allowing type patterns for all types, whether primitive or reference; aligning types with instanceof and aligning instanceof with safe casting; and allowing pattern matching to use primitive types in both nested and top-level pattern contexts. This feature was previously previewed in JDK 23.
Other goals include providing easy-to-use constructs that eliminate the risk of losing information due to unsafe casts, following the enhancements to switch in Java 5 and Java 7, and allowing switch to process values of any primitive type.
With linking runtime images without JMODs, the plan is to reduce the size of the JDK by roughly 25% by enabling the jlink tool to create custom runtime images without JDK JMOD files. This feature must be enabled by default and some JDK vendors may choose not to enable it. Goals include allowing users to link a runtime image from modules regardless of whether those modules are standalone JMOD files, modular JAR files, or part of a runtime image linked previously. Motivating this proposal is the notion that the installed size of the JDK on the file system is important in cloud environments, where container images that include an installed JDK are automatically and frequently copied over the network from container registries. Reducing the size of the JDK would improve the efficiency of these operations.
Generational Shenandoah would enhance the garbage collector with experimental generational collection capabilities to improve sustainable throughput, load-spike resistance, and memory utilization. The main goal is to provide an experimental generational mode, without breaking non-generational Shenandoah. The generational mode is intended to become the default mode in a future release.
Scoped values enable a method to share immutable data both with its callees within a thread and with child threads. Scoped values are easier to reason about than local-thread variables. They also have lower space and time costs, particularly when used together with virtual threads and structured concurrency. The scoped values API was proposed for incubation in JDK 20, proposed for preview in JDK 21, and improved and refined for JDK 22 and JDK 23. Scoped values will be previewed in JDK 24.
With the key derivation function (KDF) API, an API would be introduced for key derivation functions, which are cryptographic algorithms for deriving additional keys from a secret key and other data. A goal of this proposal is allowing security providers to implement KDF algorithms in either Java code or native code. Another goal is enabling applications to use KDF algorithms such as the HMAC (hash message authentication code)-based extract-and-expand key derivation function (RFC 5869) and Argon2 (RFC 9106).
Removing the non-generational mode of the Z Garbage Collector (ZGC) is a proposal aimed at reducing the maintenance cost of supporting two different modes. Maintaining non-generational ZGC slows the development of new features, and generational ZGC should be a better solution for most use cases than non-generational ZGC, the proposal states. The latter eventually should be replaced with the former to reduce long-term maintenance costs. The plan calls for removing the non-generational mode by obsoleting the ZGenerational option and removing the non-generational ZGC code and its tests. The non-generational mode will expire in a future release, at which point it will not be recognized by the HotSpot JVM, which will refuse to start.
Stream gatherers would enhance the stream API to support custom intermediate operations. Stream gatherers allow stream pipelines to transform data in ways that are not easily achievable with the existing built-in intermediate operations. This feature was proposed as a preview in JDK 22 and JDK 23. The API would be finalized in JDK 24. Goals include making stream pipelines more flexible and expressive and allowing custom intermediate operations to manipulate streams of infinite size.
The vector API is designed to express vector communications that reliably compile at runtime to optimal vector instructions on supported CPU architectures, thus achieving performance superior to equivalent scalar computations. The vector API previously was incubated in JDK 16 through JDK 23. It would be re-incubated in JDK 24 with no API changes and no substantial implementations relative to JDK 23. Goals of the proposal include clearly and concisely expressing a wide range of vector computations in an API that is platform-agnostic, that offers reliable runtime compilation and performance on x64 and AArch54 architectures, that degrades gracefully and still functions when a vector computation cannot be expressed at runtime, and that aligns with Project Valhalla, leveraging enhancements to the Java object model.
The class-file API, previously previewed in JDK 22 and JDK 23, would be finalized in JDK 24, with minor changes. This API provides a standard API for parsing, generating, and transforming Java class files. It aims to provide an API for processing class files that tracks the class file format defined by the Java Virtual Machine specification. A second goal is to enable JDK components to migrate to the standard API, and eventually remove the JDK’s internal copy of the third-party ASM library. Changes since the second preview include a renaming of enum values, removal of some fields, the addition of methods and method overloads, methods renamed, and removal of interfaces and methods deemed unnecessary.
Late barrier expansion for the G1 garbage collector is intended to simplify the implementation of G1’s barriers. The G1 garbage collector’s barriers record information about application memory accesses, by shifting their expansion from early in the C2 compilation pipeline to later. Goals include reducing the execution time of C2 compilation when using the G1 collector, making G1 barriers comprehensible to HotSpot developers who lack a deep understanding of C2, and guaranteeing that C2 preserves invariants about the relative ordering of memory accesses, safepoints, and barriers. A fourth feature is preserving the quality of C2-generated JIT (just-in-time)-compiled code, in terms of speed and size.
The first JDK 24-targeted feature, officially called “Prepare to Restrict the Use of JNI,” calls for issuing warnings about uses of JNI and adjusting the foreign function and memory (FFM) API, featured in JDK 22, to issue warnings in a consistent manner. These warnings are intended to prepare for a future release that ensures integrity by default by uniformly restricting JNI and the FFM API. Goals of the plan include preserving JNI as a standard way to interoperate with native code, preparing the Java ecosystem for future releases that disallow interoperation with native code by default, and aligning the use of JNI and the FFM API so library maintainers can migrate from one to the other without requiring developers to change command-line options.
Additional features targeting JDK 24 will be determined during the next several weeks. Other potential Java 24 features include structured concurrency, which simplify concurrent programming, and string templates, a feature previewed in JDK 21 and JDK 22 but dropped from JDK 23.
The most recent LTS release, JDK 21, arrived in September 2023 and is due to get at least five years of Premier support from Oracle. The next LTS version, JDK 25, is due in September 2025. LTS releases have dominated Java adoption, which means adoption of JDK 23 and JDK 24 could be on the low end as users await JDK 25.
{kind=link}
Page processed in 1.277 seconds.
Powered by SimplePie 1.3.1, Build 20121030095402. Run the SimplePie Compatibility Test. SimplePie is © 2004–2024, Ryan Parman and Geoffrey Sneddon, and licensed under the BSD License.